向量搜索基础
向量搜索,也称为相似性搜索或最近邻搜索,是一种强大的技术,用于查找与给定输入最相似的项目。用例包括理解用户意图的语义搜索、推荐(例如,音乐应用中的“您可能喜欢的其他歌曲”功能)、图像识别和欺诈检测。有关向量搜索的更多背景信息,请参阅最近邻搜索。
向量嵌入
与依赖精确关键词匹配的传统搜索方法不同,向量搜索使用向量嵌入——文本、图像或音频等数据的数值表示。这些嵌入以多维向量的形式存储,捕捉含义、上下文或结构中更深层次的模式和相似性。例如,大型语言模型 (LLM) 可以根据输入文本创建向量嵌入,如下图所示。
相似性搜索
向量嵌入是高维空间中的一个向量。其位置和方向捕捉了对象之间有意义的关系。向量搜索通过将查询向量与存储的向量进行比较并返回最接近的匹配项来查找最相似的结果。OpenSearch 使用 k 最近邻 (k-NN) 算法来高效识别最相似的向量。与依赖精确词语匹配的关键词搜索不同,向量搜索通过衡量高维空间中的距离来衡量相似性。
在下图中,Wild West 和 Broncos 的向量彼此更接近,而它们都远离 Basketball,这反映了它们在语义上的差异。
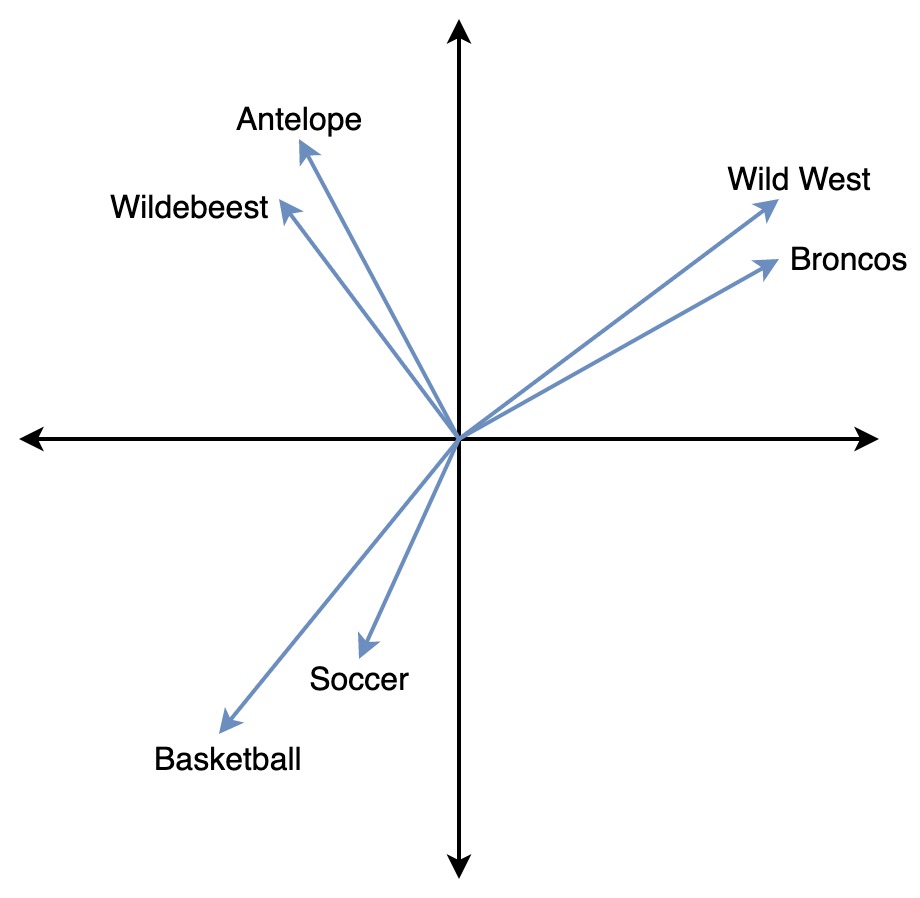
要了解有关 OpenSearch 支持的向量搜索类型的更多信息,请参阅向量搜索技术。
计算相似性
向量相似性衡量两个向量在多维空间中的接近程度,有助于完成最近邻搜索和按相关性排序结果等任务。OpenSearch 支持多种距离度量(空间)来计算向量相似性:
- L1(曼哈顿距离):计算向量分量之间绝对差的总和。
- L2(欧几里得距离):计算平方差之和的平方根,使其对幅度敏感。
- L∞(切比雪夫距离):仅考虑对应向量元素之间的最大绝对差。
- 余弦相似性:测量向量之间的角度,侧重于方向而非幅度。
- 内积:根据向量点积确定相似性,这对于排名很有用。
- 汉明距离:计算二进制向量中不同元素的数量。
- 汉明位:与汉明距离应用相同的原理,但针对二进制编码数据进行了优化。
要了解有关距离度量的更多信息,请参阅空间。