高效 k-NN 过滤
您可以使用 lucene 或 faiss 引擎执行高效的 k-NN 过滤。
Lucene k-NN 过滤器实现
OpenSearch 2.2 版本引入了对使用 HNSW 图在 Lucene 引擎上运行 k-NN 搜索的支持。从基于 Lucene 9.4 版本的 2.4 版本开始,您可以将 Lucene 过滤器用于 k-NN 搜索。
当您为 k-NN 搜索指定 Lucene 过滤器时,Lucene 算法会决定是执行带预过滤的精确 k-NN 搜索,还是执行带修改后过滤的近似搜索。该算法使用以下变量:
- N:索引中的文档数量。
- P:过滤应用后文档子集中的文档数量 (P <= N)。
- k:响应中要返回的最大向量数量。
下面的流程图概述了 Lucene 算法。
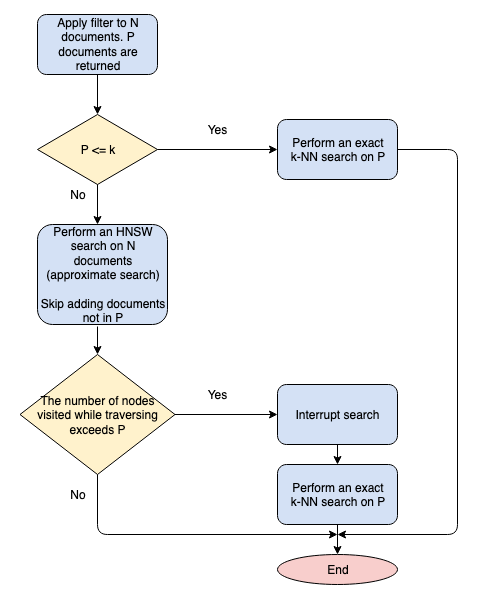
有关 Lucene 过滤实现和底层 KnnVectorQuery 的更多信息,请参阅 Apache Lucene 文档。
使用 Lucene k-NN 过滤器
假设一个数据集包含 12 个酒店信息文档。下图显示了 xy 坐标平面上按位置显示的所有酒店。此外,评级在 8 到 10 之间(含 8 和 10)的酒店点用橙色点表示,提供停车场的酒店用绿色圆圈表示。搜索点用红色标示。
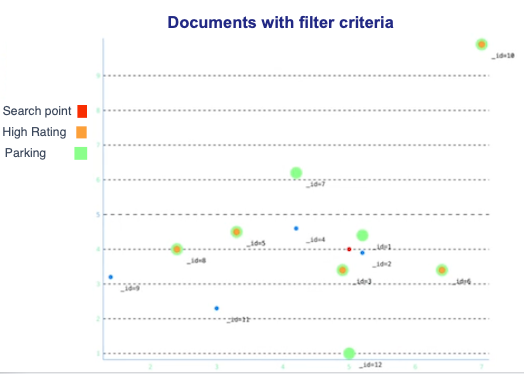
在此示例中,您将创建一个索引,并搜索距离搜索位置最近的三个高评分且提供停车场的酒店。
步骤 1:创建新索引
在使用过滤器运行 k-NN 搜索之前,您需要创建一个包含 knn_vector 字段的索引。对于此字段,您需要在映射中指定 lucene 作为引擎,hnsw 作为 method。
以下请求创建一个名为 hotels-index 的新索引,其中包含一个名为 location 的 knn-filter 字段:
PUT /hotels-index
{
"settings": {
"index": {
"knn": true,
"knn.algo_param.ef_search": 100,
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"location": {
"type": "knn_vector",
"dimension": 2,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "lucene",
"parameters": {
"ef_construction": 100,
"m": 16
}
}
}
}
}
}
步骤 2:向索引添加数据
接下来,向索引添加数据。
以下请求添加 12 个包含酒店位置、评分和停车场信息的文档:
POST /_bulk
{ "index": { "_index": "hotels-index", "_id": "1" } }
{ "location": [5.2, 4.4], "parking" : "true", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "2" } }
{ "location": [5.2, 3.9], "parking" : "false", "rating" : 4 }
{ "index": { "_index": "hotels-index", "_id": "3" } }
{ "location": [4.9, 3.4], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "4" } }
{ "location": [4.2, 4.6], "parking" : "false", "rating" : 6}
{ "index": { "_index": "hotels-index", "_id": "5" } }
{ "location": [3.3, 4.5], "parking" : "true", "rating" : 8 }
{ "index": { "_index": "hotels-index", "_id": "6" } }
{ "location": [6.4, 3.4], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "7" } }
{ "location": [4.2, 6.2], "parking" : "true", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "8" } }
{ "location": [2.4, 4.0], "parking" : "true", "rating" : 8 }
{ "index": { "_index": "hotels-index", "_id": "9" } }
{ "location": [1.4, 3.2], "parking" : "false", "rating" : 5 }
{ "index": { "_index": "hotels-index", "_id": "10" } }
{ "location": [7.0, 9.9], "parking" : "true", "rating" : 9 }
{ "index": { "_index": "hotels-index", "_id": "11" } }
{ "location": [3.0, 2.3], "parking" : "false", "rating" : 6 }
{ "index": { "_index": "hotels-index", "_id": "12" } }
{ "location": [5.0, 1.0], "parking" : "true", "rating" : 3 }
步骤 3:使用过滤器搜索数据
现在您可以创建带过滤器的 k-NN 搜索。在 k-NN 查询子句中,包含用于搜索最近邻的兴趣点、要返回的最近邻数量 (k) 以及包含限制条件的过滤器。根据您希望过滤器的限制程度,您可以在单个请求中添加多个查询子句。
以下请求创建一个 k-NN 查询,用于搜索坐标为 [5, 4] 附近排名前三的酒店,这些酒店的评分在 8 到 10 之间(含 8 和 10),并且提供停车场:
POST /hotels-index/_search
{
"size": 3,
"query": {
"knn": {
"location": {
"vector": [
5,
4
],
"k": 3,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 8,
"lte": 10
}
}
},
{
"term": {
"parking": "true"
}
}
]
}
}
}
}
}
}
响应返回距离搜索点最近且符合过滤条件的三个酒店。
{
"took" : 47,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.72992706,
"hits" : [
{
"_index" : "hotels-index",
"_id" : "3",
"_score" : 0.72992706,
"_source" : {
"location" : [
4.9,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "6",
"_score" : 0.3012048,
"_source" : {
"location" : [
6.4,
3.4
],
"parking" : "true",
"rating" : 9
}
},
{
"_index" : "hotels-index",
"_id" : "5",
"_score" : 0.24154587,
"_source" : {
"location" : [
3.3,
4.5
],
"parking" : "true",
"rating" : 8
}
}
]
}
}
有关构建过滤器的更多方法,请参阅构建过滤器。
Faiss k-NN 过滤器实现
对于 k-NN 搜索,您可以将 faiss 过滤器与 HNSW 算法(OpenSearch 2.9 版本及更高版本)或 IVF 算法(OpenSearch 2.10 版本及更高版本)一起使用。
当您为 k-NN 搜索指定 Faiss 过滤器时,Faiss 算法会决定是执行带预过滤的精确 k-NN 搜索,还是执行带修改后过滤的近似搜索。该算法使用以下变量:
- N:索引中的文档数量。
- P:过滤应用后文档子集中的文档数量 (P <= N)。
- k:响应中要返回的最大向量数量。
- R:执行过滤后的近似最近邻搜索后返回的结果数量。
- FT(过滤阈值):在
knn.advanced.filtered_exact_search_threshold设置中定义的索引级别阈值,指定何时切换到精确搜索。 - MDC(最大距离计算):如果未设置
FT(过滤阈值),则精确搜索中允许的最大距离计算次数。此值无法更改。
下面的流程图概述了 Faiss 算法。
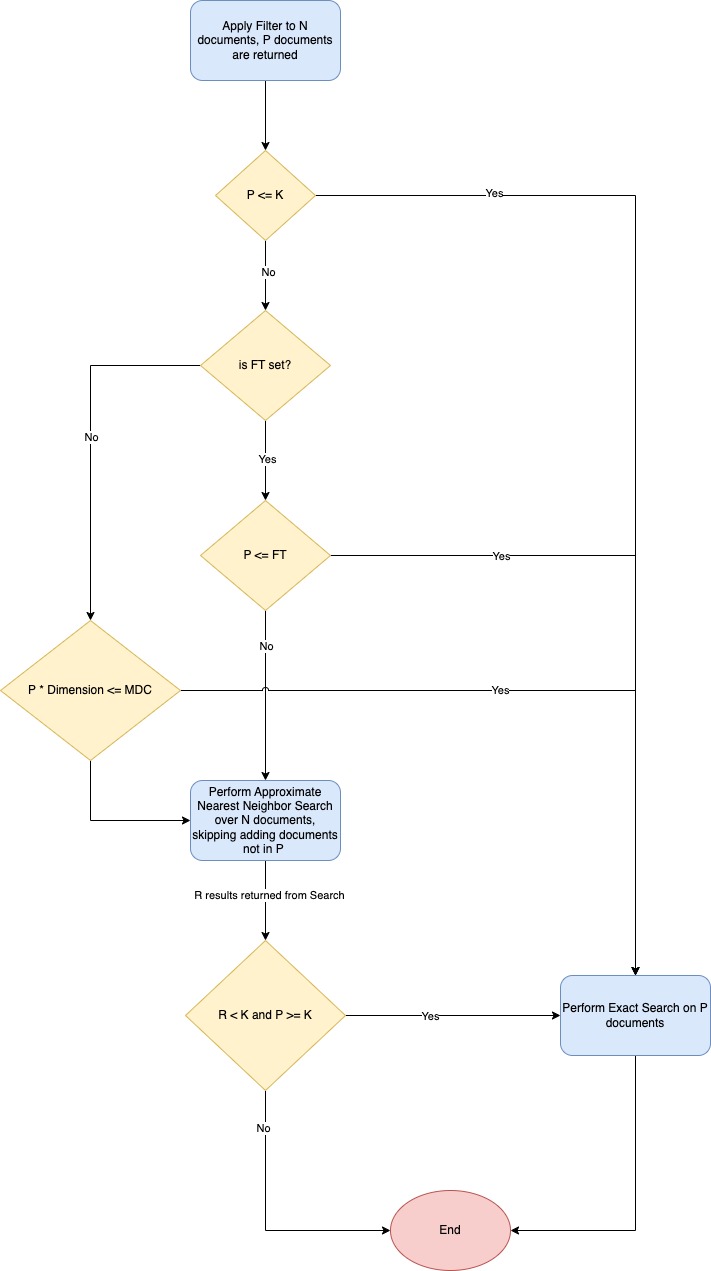
使用 Faiss 高效过滤器
假设一个索引包含电子商务应用程序中不同衬衫的信息。您想找到与您已有衬衫相似的评分最高的衬衫,但希望按衬衫尺寸限制结果。
在此示例中,您将创建一个索引并搜索与您提供的衬衫相似的衬衫。
步骤 1:创建新索引
在使用过滤器运行 k-NN 搜索之前,您需要创建一个包含 knn_vector 字段的索引。对于此字段,您需要在映射中指定 faiss 和 hnsw 作为 method。
以下请求创建一个包含衬衫向量表示的索引:
PUT /products-shirts
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"item_vector": {
"type": "knn_vector",
"dimension": 3,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
}
}
}
}
}
步骤 2:向索引添加数据
接下来,向索引添加数据。
以下请求添加 12 个包含衬衫信息(包括其向量表示、尺寸和评分)的文档:
POST /_bulk?refresh
{ "index": { "_index": "products-shirts", "_id": "1" } }
{ "item_vector": [5.2, 4.4, 8.4], "size" : "large", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "2" } }
{ "item_vector": [5.2, 3.9, 2.9], "size" : "small", "rating" : 4 }
{ "index": { "_index": "products-shirts", "_id": "3" } }
{ "item_vector": [4.9, 3.4, 2.2], "size" : "xlarge", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "4" } }
{ "item_vector": [4.2, 4.6, 5.5], "size" : "large", "rating" : 6}
{ "index": { "_index": "products-shirts", "_id": "5" } }
{ "item_vector": [3.3, 4.5, 8.8], "size" : "medium", "rating" : 8 }
{ "index": { "_index": "products-shirts", "_id": "6" } }
{ "item_vector": [6.4, 3.4, 6.6], "size" : "small", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "7" } }
{ "item_vector": [4.2, 6.2, 4.6], "size" : "small", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "8" } }
{ "item_vector": [2.4, 4.0, 3.0], "size" : "small", "rating" : 8 }
{ "index": { "_index": "products-shirts", "_id": "9" } }
{ "item_vector": [1.4, 3.2, 9.0], "size" : "small", "rating" : 5 }
{ "index": { "_index": "products-shirts", "_id": "10" } }
{ "item_vector": [7.0, 9.9, 9.0], "size" : "xlarge", "rating" : 9 }
{ "index": { "_index": "products-shirts", "_id": "11" } }
{ "item_vector": [3.0, 2.3, 2.0], "size" : "large", "rating" : 6 }
{ "index": { "_index": "products-shirts", "_id": "12" } }
{ "item_vector": [5.0, 1.0, 4.0], "size" : "large", "rating" : 3 }
步骤 3:使用过滤器搜索数据
现在您可以创建带过滤器的 k-NN 搜索。在 k-NN 查询子句中,包含用于搜索相似衬衫的向量表示、要返回的最近邻数量 (k) 以及按尺寸和评分过滤的条件。
以下请求搜索评分在 7 到 10 之间(含 7 和 10)的小尺寸衬衫:
POST /products-shirts/_search
{
"size": 2,
"query": {
"knn": {
"item_vector": {
"vector": [
2, 4, 3
],
"k": 10,
"filter": {
"bool": {
"must": [
{
"range": {
"rating": {
"gte": 7,
"lte": 10
}
}
},
{
"term": {
"size": "small"
}
}
]
}
}
}
}
}
}
响应返回两个匹配的文档。
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.8620689,
"hits": [
{
"_index": "products-shirts",
"_id": "8",
"_score": 0.8620689,
"_source": {
"item_vector": [
2.4,
4,
3
],
"size": "small",
"rating": 8
}
},
{
"_index": "products-shirts",
"_id": "6",
"_score": 0.029691212,
"_source": {
"item_vector": [
6.4,
3.4,
6.6
],
"size": "small",
"rating": 9
}
}
]
}
}
有关构建过滤器的更多方法,请参阅构建过滤器。
构建过滤器
对于相同条件,有多种方法可以构建过滤器。例如,您可以使用以下构造来创建返回提供停车场的酒店的过滤器:
should子句中的term查询子句should子句中的wildcard查询子句should子句中的regexp查询子句- 一个
must_not子句,用于排除parking设置为false的酒店。
以下请求展示了搜索提供停车场的酒店的这四种不同方法:
POST /hotels-index/_search
{
"size": 3,
"query": {
"knn": {
"location": {
"vector": [ 5.0, 4.0 ],
"k": 3,
"filter": {
"bool": {
"must": {
"range": {
"rating": {
"gte": 1,
"lte": 6
}
}
},
"should": [
{
"term": {
"parking": "true"
}
},
{
"wildcard": {
"parking": {
"value": "t*e"
}
}
},
{
"regexp": {
"parking": "[a-zA-Z]rue"
}
}
],
"must_not": [
{
"term": {
"parking": "false"
}
}
],
"minimum_should_match": 1
}
}
}
}
}
}