在 OpenSearch Dashboards 中构建 AI 搜索工作流
在 OpenSearch Dashboards 中,您可以使用 AI 搜索流(AI Search Flows)迭代地构建和测试包含摄取和搜索管道的工作流。使用 UI 编辑器构建工作流简化了人工智能和机器学习 (AI/ML) 用例的创建,包括 ML 推理处理器,例如向量搜索和检索增强生成 (RAG)。有关可用 AI 搜索类型(包括语义搜索、混合搜索、RAG 和多模态搜索)的示例配置,请参阅配置 AI 搜索类型。
工作流最终确定后,您可以将其导出为工作流模板,以便在多个集群中重新创建相同的资源。
前置知识
摄取管道和搜索管道支持 OpenSearch 中摄取和搜索操作不同阶段的数据转换。摄取管道由一系列摄取处理器组成,而搜索管道由搜索请求处理器和/或搜索响应处理器组成。您可以组合这些处理器来创建满足您数据处理需求的自定义管道。
这些管道在三个关键阶段修改数据:
- 摄取:在将文档摄取到索引之前对其进行转换。
- 搜索请求:在执行搜索之前转换搜索请求。
- 搜索响应:在执行搜索之后但在返回响应之前,转换搜索响应,包括结果中的文档。
在 OpenSearch 中,您可以集成托管在第三方平台上的模型,并直接在 OpenSearch 中使用它们的推理功能。摄取管道和搜索管道都提供ML 推理处理器,允许您在摄取和搜索过程中使用外部托管模型在管道中进行推理。
访问 AI 搜索流
要访问 AI 搜索流,请转到 OpenSearch Dashboards,然后从顶部菜单中选择 OpenSearch Plugins > AI Search Flows。
预设模板
在主页上,选择 New workflow 选项卡,或选择右侧的 Create workflow 按钮。这将打开一系列针对不同用例设计的预设模板,每个模板都具有一组独特的预配置摄取和搜索处理器。这些模板主要用于两个目的:
- 快速测试 AI/ML 解决方案:如果您的已部署模型具有定义的接口,您可以点击几下即可在集群中设置一个基本解决方案。有关更多信息,请参阅示例:带有 RAG 的语义搜索。
- 自定义/高级解决方案的起点:每个模板都为构建自定义解决方案提供了一个结构化的起点。您可以修改和扩展这些模板以适应您的特定需求。
工作流编辑器
您可以在工作流编辑器中构建和测试您的摄取和搜索工作流,如下图所示。
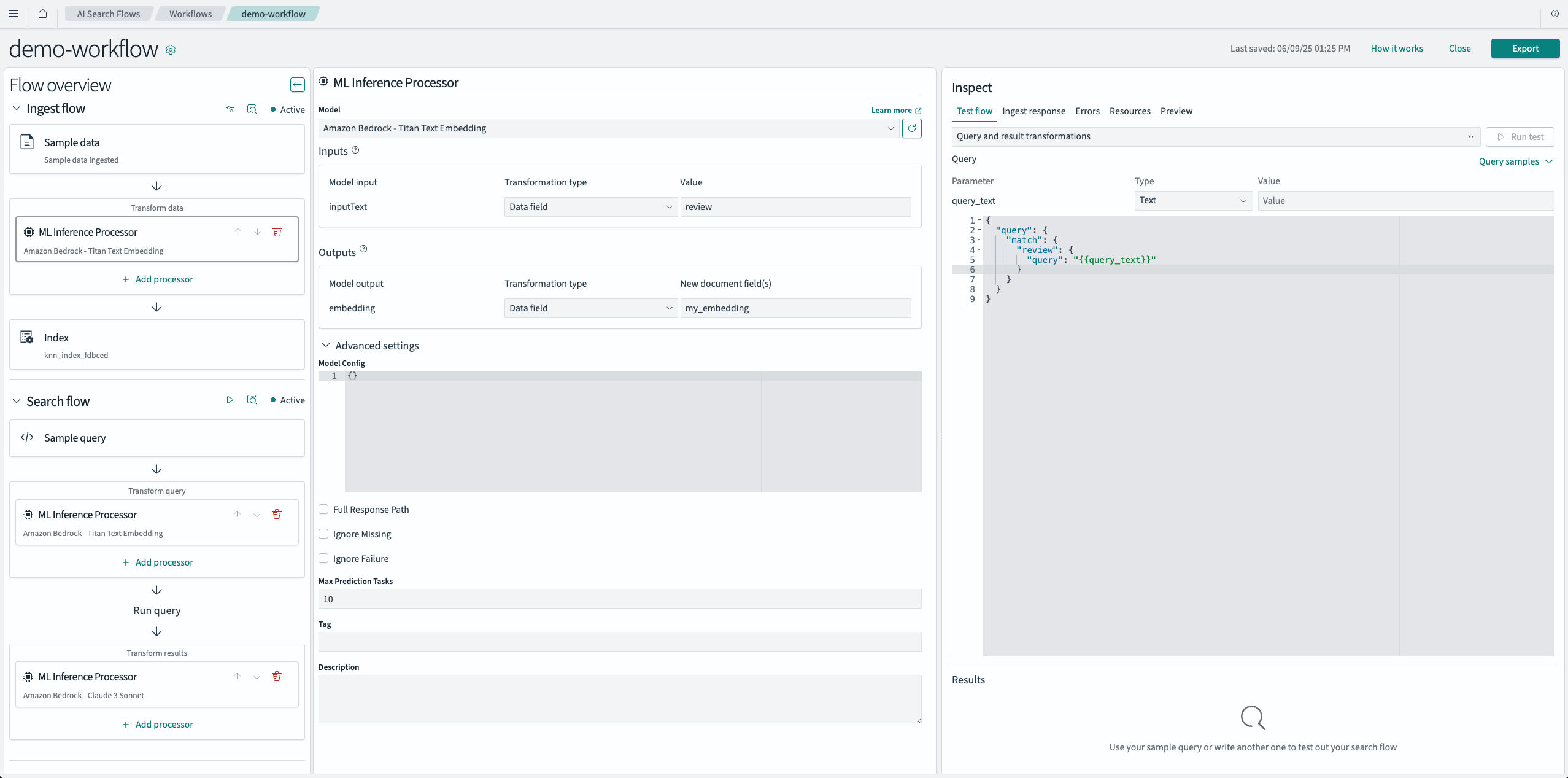
工作流编辑器像集成开发环境 (IDE) 一样组织,包括三个主要组件:
- 流程概览:一个可折叠的导航面板,用于选择摄取流和搜索流中的不同组件。在此面板中,您可以添加、删除或重新排序处理器。如果您已经有了一个已填充的索引并且只需要一个搜索流,则可以禁用摄取流。
- 组件详情:用于配置单个组件详情的中央面板。从流程概览中选择一个组件将在此面板中填充相关详情。
- 检查:一组用于与您的工作流交互的选项卡。
- 测试流:允许您运行搜索流(无论是否带有搜索管道),并以表格或原始 JSON 格式查看结果。
- 摄取响应:显示更新摄取流后的 API 响应。
- 错误:显示更新、摄取操作或搜索的最新错误。当出现新错误时,此选项卡会自动打开。
- 资源:列出与工作流关联的 OpenSearch 资源,包括最多一个摄取管道、一个索引和一个搜索管道。要查看资源详细信息,请选择检查。
- 预览:一个只读的可视化,显示数据如何在您的摄取和搜索流中移动。当您对流程进行更改时,此视图会自动更新。您还可以切换到 JSON 选项卡以查看底层模板配置。
示例:带有 RAG 的语义搜索
以下示例使用已部署的 Titan Text Embedding 模型和托管在 Amazon Bedrock 上的 Anthropic Claude 模型来构建摄取管道、索引和搜索管道,以执行向量搜索和 RAG。
我们强烈建议使用具有完整模型接口的模型。有关示例配置列表,请参阅模型。
- 在 Workflows 页面上,选择 New workflow 选项卡,如下图所示。
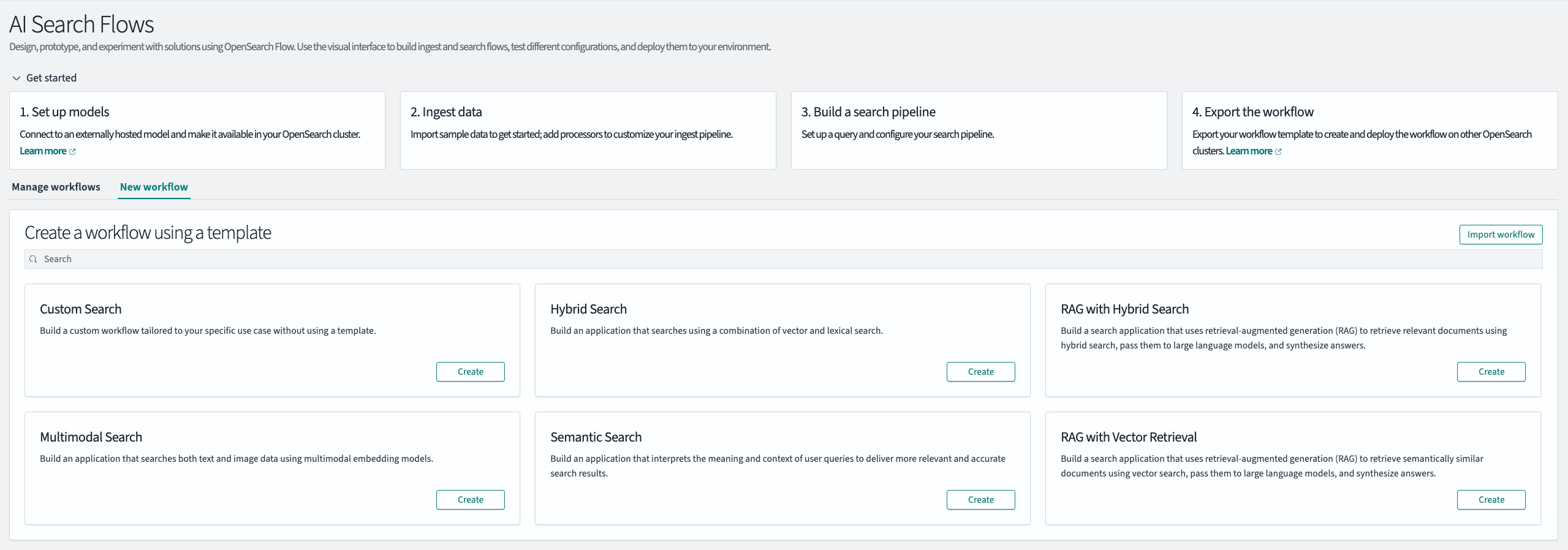
- 在 RAG with Vector Retrieval 模板中,选择 Create。
-
提供一些基本详细信息,如下图所示:
- 唯一的工作流名称和描述
- 用于生成向量嵌入的嵌入模型
- 用于执行 RAG 的大型语言模型 (LLM)
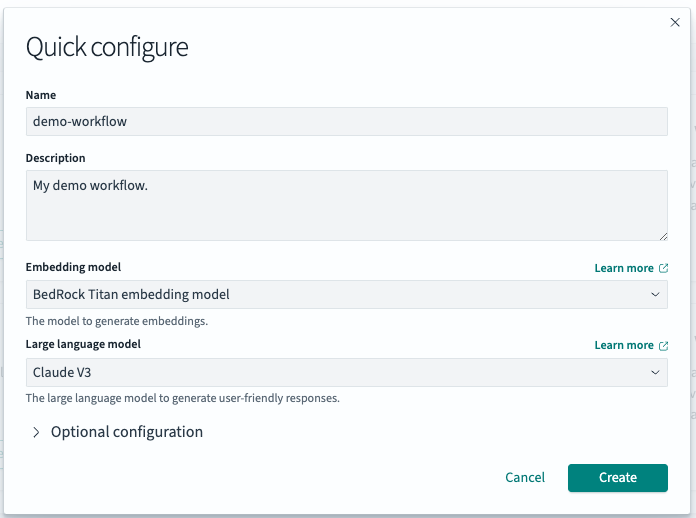
对于其他选项,例如将持久化到索引中的文本字段和向量字段名称,请选择 Optional configuration。您可以随时更新这些设置。
- 选择 Create 以预填充配置并自动导航到 Workflow Details 页面,您可以在其中配置您的摄取流。
-
要提供示例数据,请从 Flow overview 中选择 Sample data。然后选择 Import data。您可以手动输入数据、上传本地
.jsonl文件,或从现有索引中检索示例文档,如下图所示。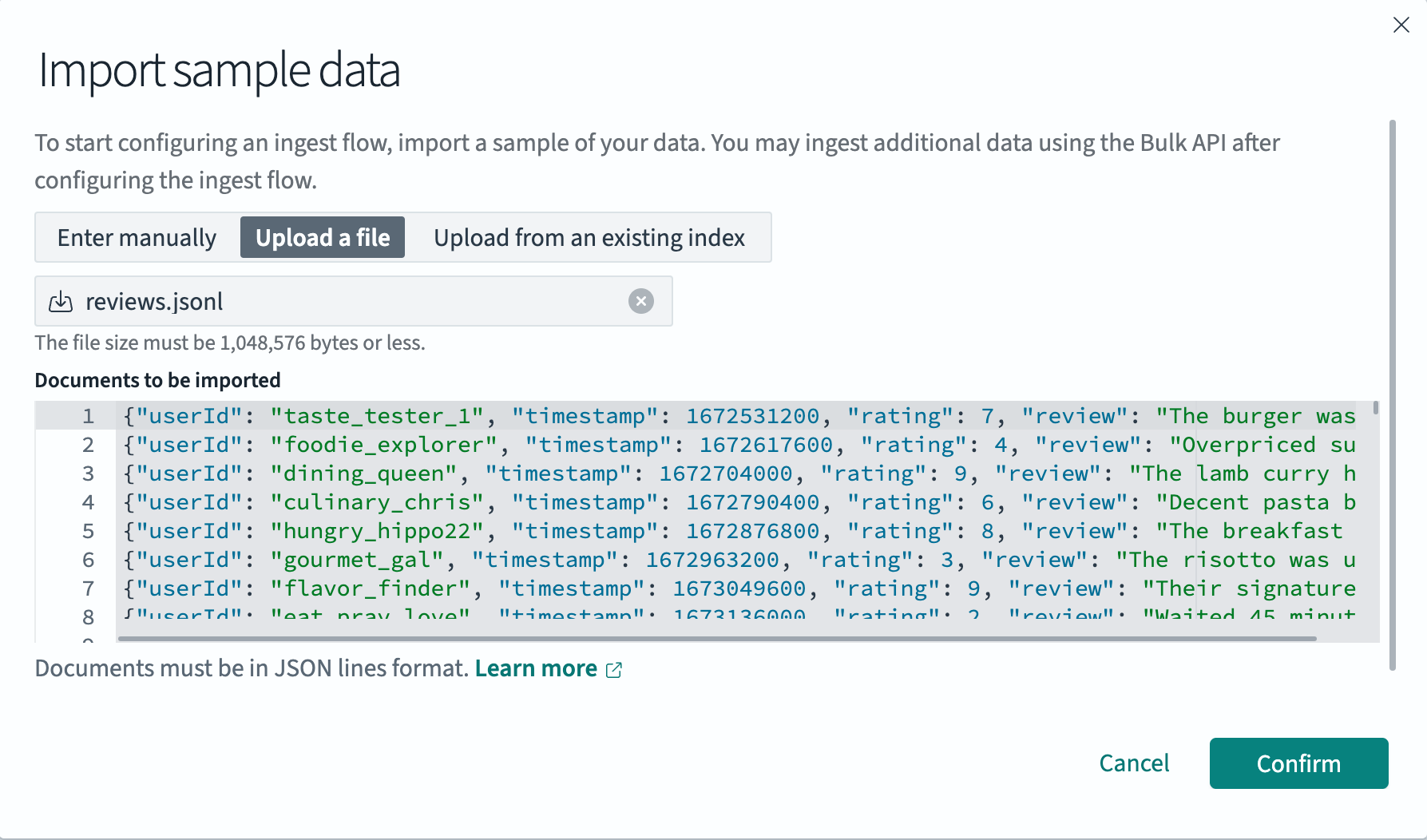
该表单预期数据采用 JSON Lines 格式,其中每一行代表一个独立的文档。此过程类似于批量摄取操作。完成后,选择 Confirm。
-
在 Flow overview 面板中,选择最顶部的 ML Inference Processor。此处理器预填充了用于将数据映射到预期模型输入和从预期模型输出的配置。Inputs 部分将目标文档字段映射到模型输入字段,为该字段生成向量嵌入。Outputs 部分将模型输出字段映射到存储在索引中的新字段,如下图所示。
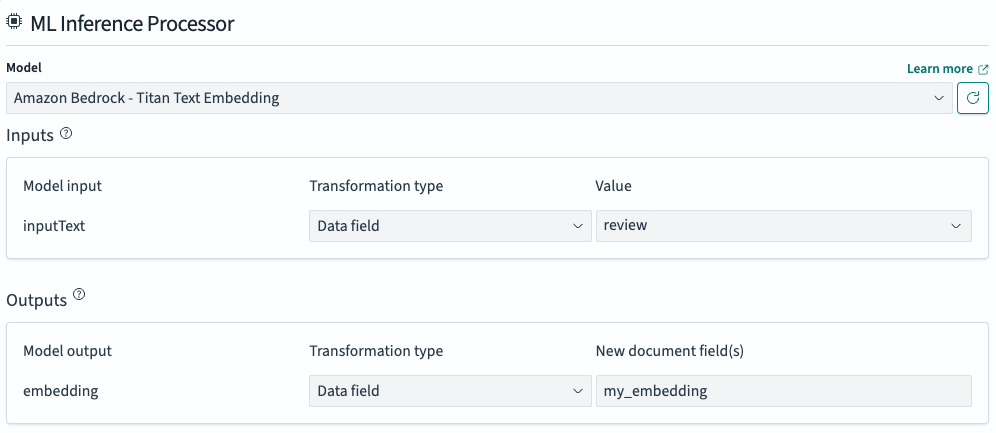
有关支持复杂数据模式和模型接口的转换类型的更多信息,请参阅高级数据转换。
- 在 Flow overview 面板中,选择 Index。该索引已预填充所选用例所需的索引配置。例如,对于向量搜索,
my_embedding字段被映射为knn_vector,并且该索引被指定为向量索引 (index.knn: true),如下图所示。您可以根据需要修改此配置。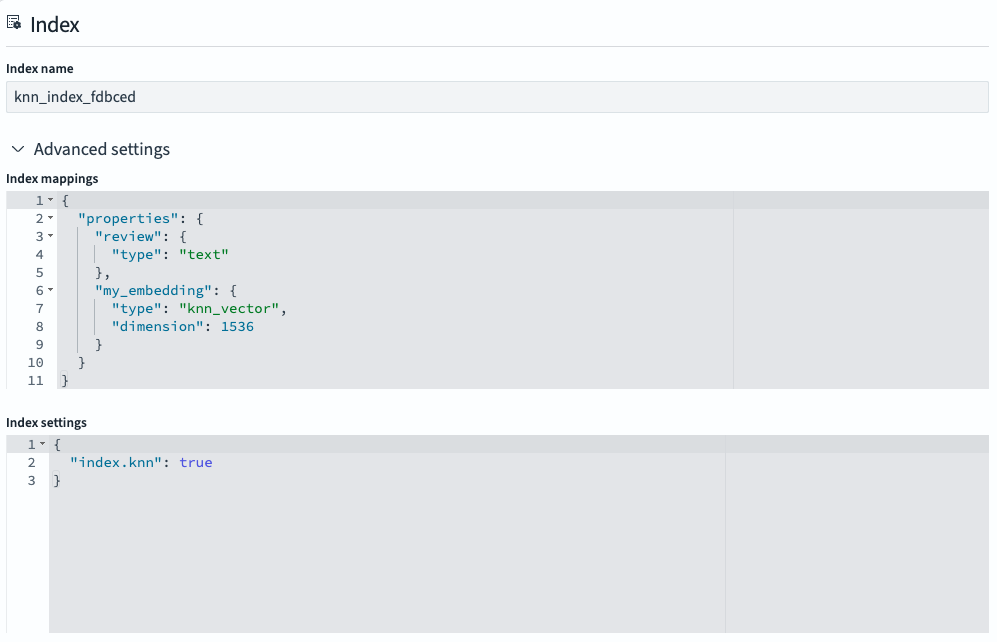
- 选择 Flow overview 底部的 Update ingest flow 来构建已配置的摄取管道和索引,并摄取提供的示例数据。然后转到 Inspect 下的 Test flow 来搜索新创建的索引并验证转换后的文档是否按预期显示。在此示例中,验证每个摄取文档是否都生成了向量嵌入,如下图所示。
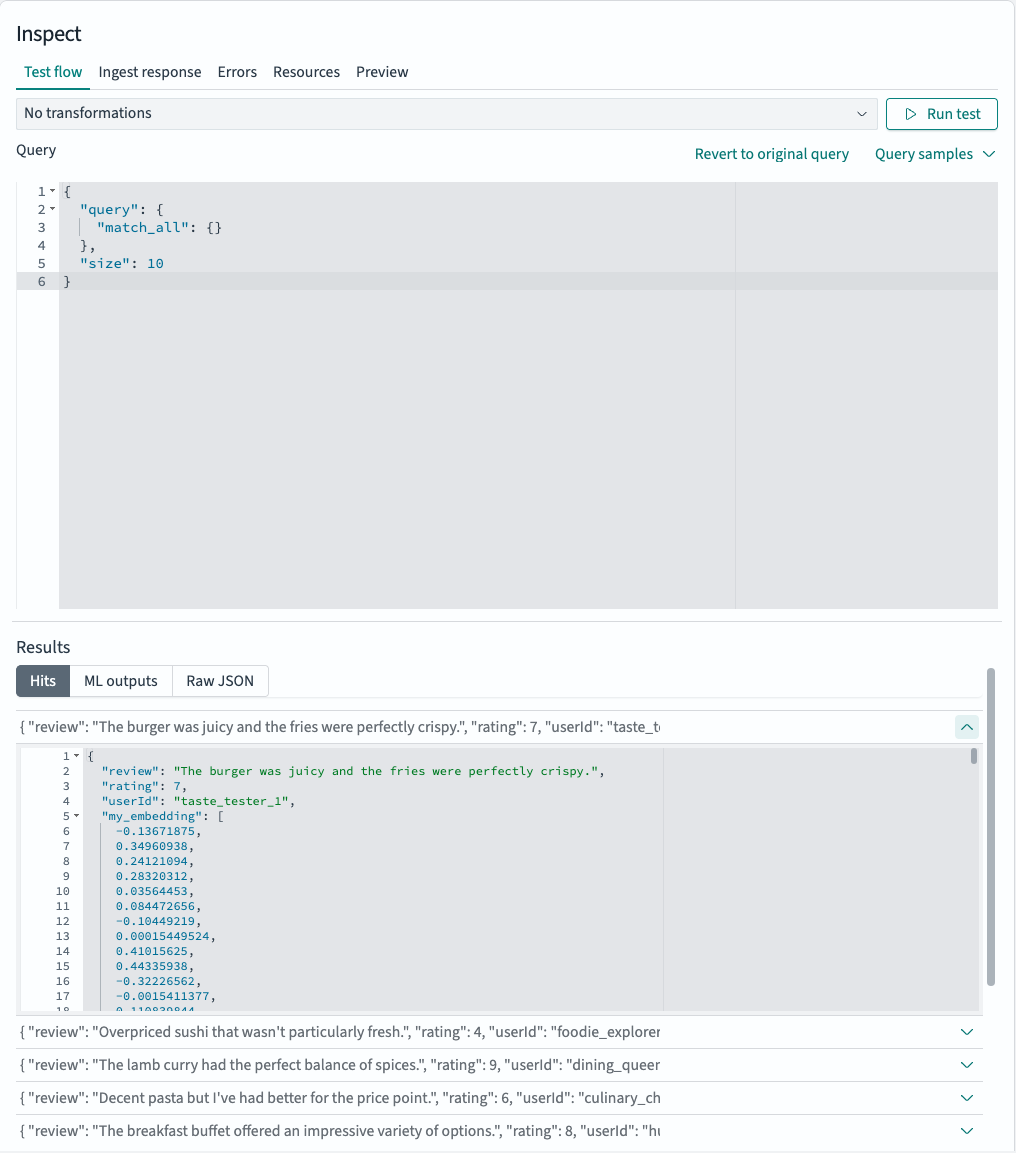
-
要配置您的搜索流,请在 Flow overview > Transform query 下选择 ML Inference Processor,如下图所示。此处理器解析您要为其生成向量嵌入的搜索查询输入。在此示例中,它将
query.match.review.query中的值传递给嵌入模型。
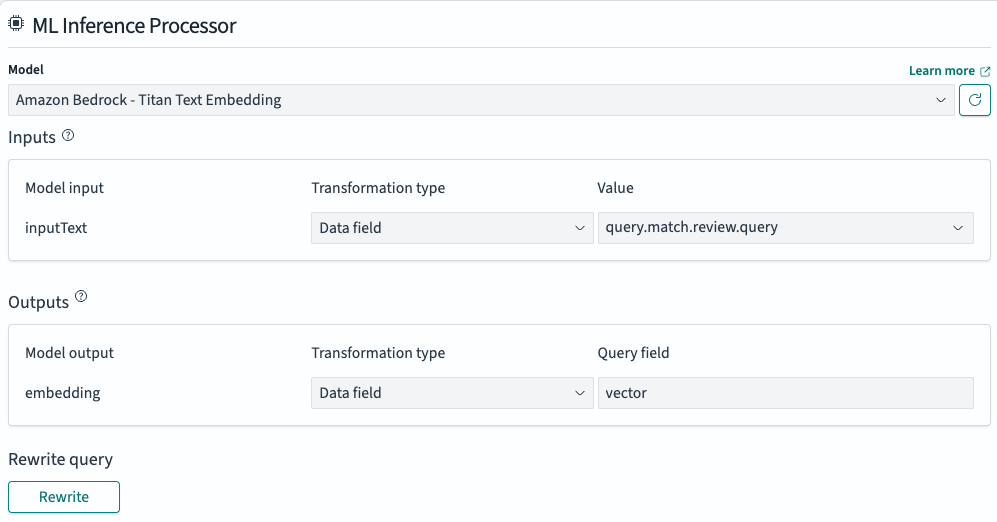
处理器还会执行查询重写,以使用模型生成的向量嵌入来生成
knn查询。选择 Rewrite query 以查看其详细信息,如下图所示。这种方法抽象了复杂的查询详细信息,提供了一个简单的查询接口,该接口使用搜索管道来执行高级查询生成。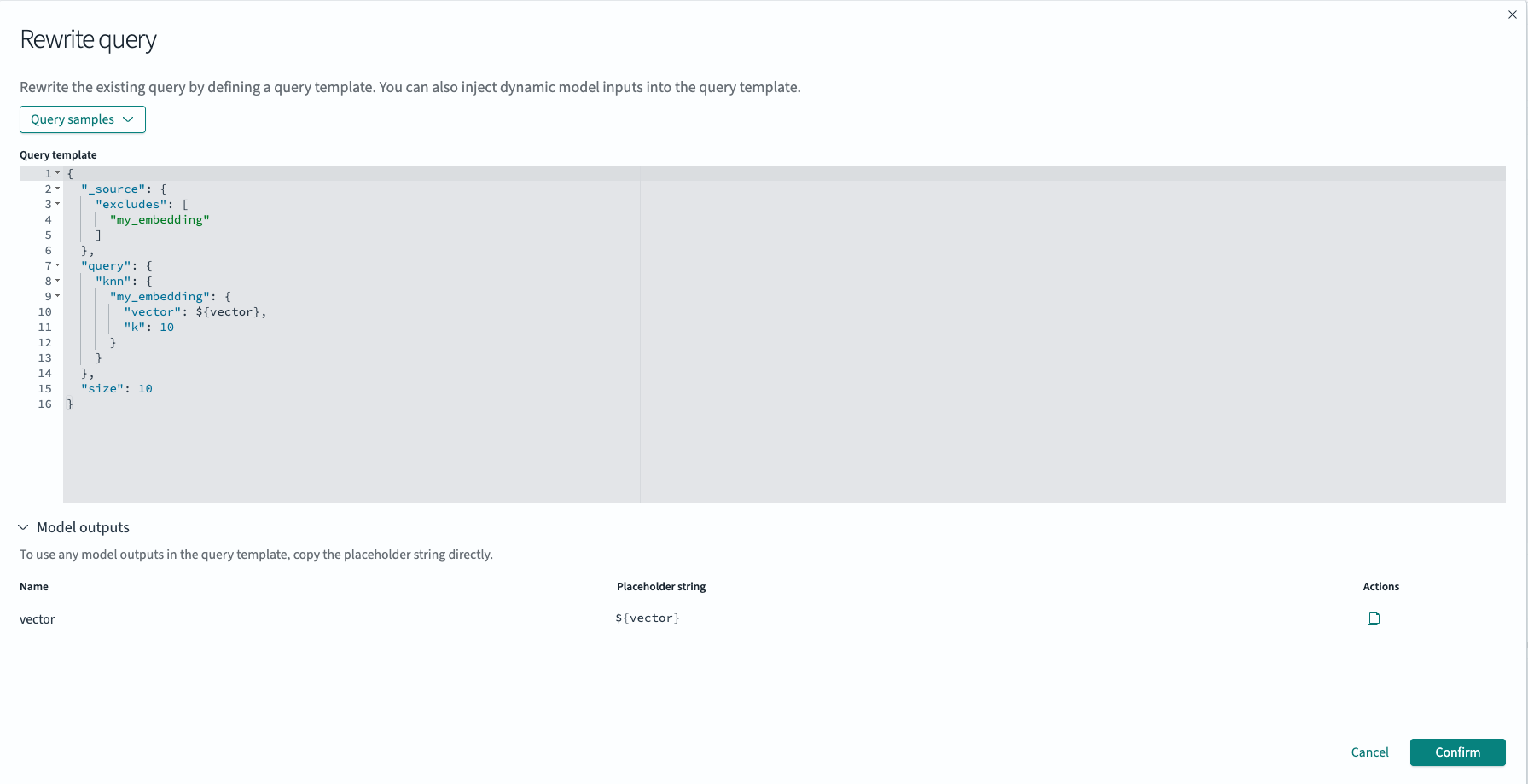
- 要配置您的搜索结果转换,请在 Flow overview > Transform response 下选择 ML Inference Processor,如下图所示。Claude LLM 用于处理返回的结果并生成人类可读的响应。
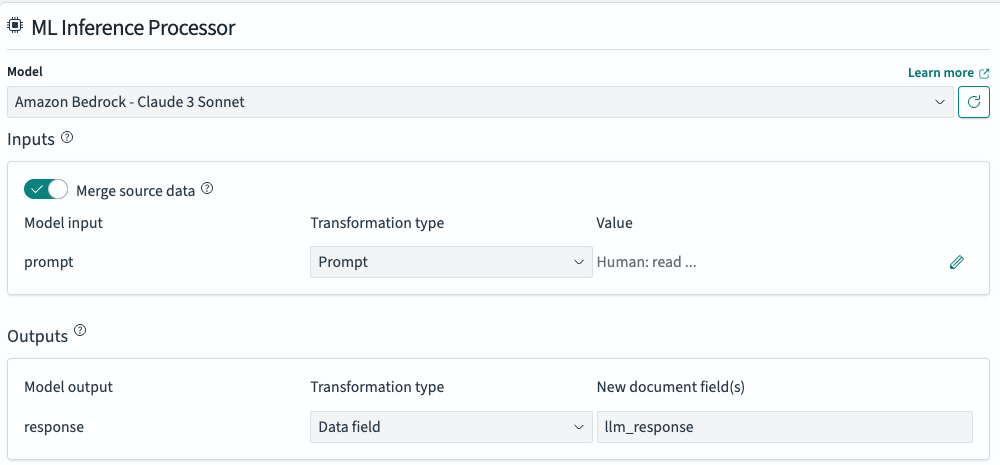
在 Inputs 下,选择prompt条目旁边的铅笔图标。这将打开一个弹出窗口,其中包含一个预配置的提示模板,用于总结返回的文档,如下图所示。您可以根据需要修改此模板;有几个预设可用作起点。您还可以添加、更新或删除输入变量,其中包括您希望动态注入到 LLM 中作为上下文信息的返回文档中的数据。默认选项收集所有review数据并总结结果。选择 Save 以应用您的更改。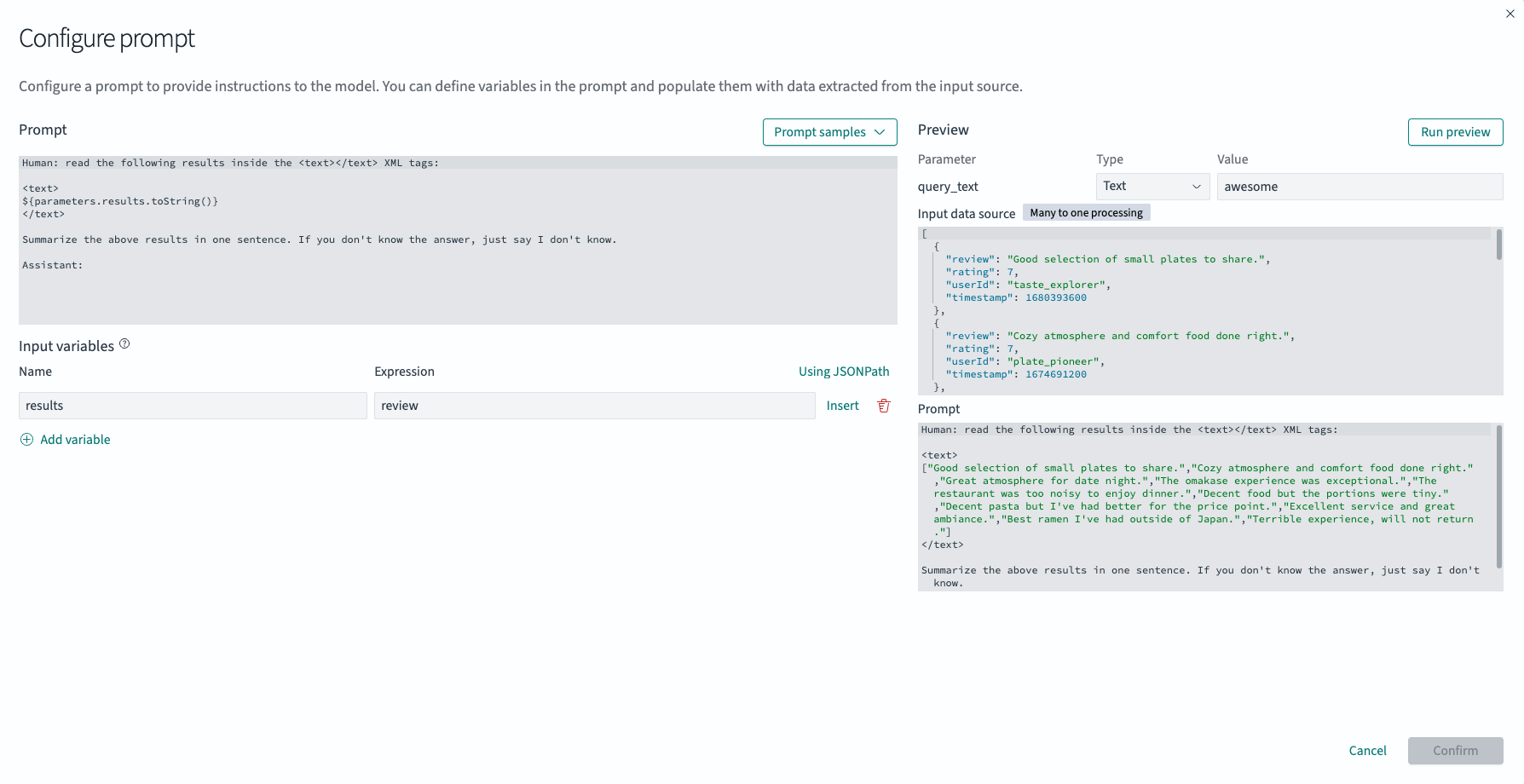
- 要构建搜索管道,请选择 Create search flow。Inspect 部分会自动导航到 Test flow 组件,您可以在其中测试不同的查询并运行搜索,如下图所示。您可以使用用
{{ }}括起来的变量来快速测试不同的查询值,而无需修改基本查询。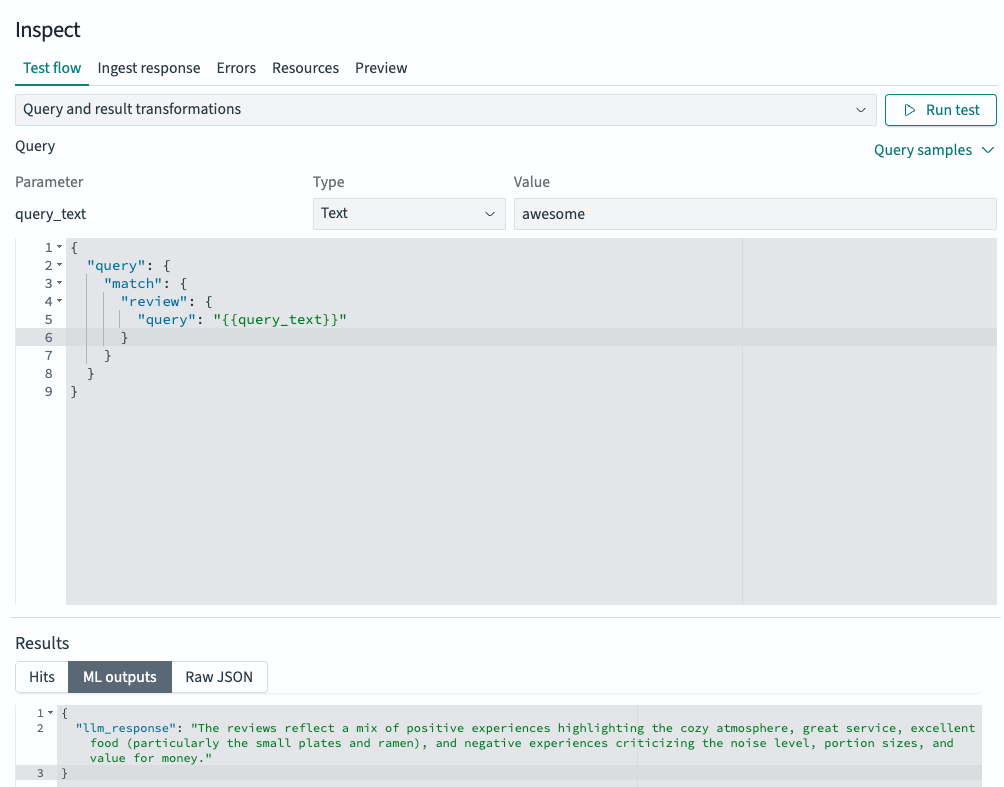
- 要查看搜索结果,请选择 Run test。您可以将结果视为格式化的命中列表,或作为原始 JSON 搜索响应。
- 根据您的用例,您可以按以下方式修改配置:
- 试验不同的查询参数。
- 尝试不同的查询。
- 修改 Transform query 或 Transform results 下的现有处理器。
- 在 Transform query 或 Transform results 下添加或删除处理器。
- 要导出您的工作流,请选择标题中的 Export。显示的数据代表工作流模板,其中包含您创建的 OpenSearch 资源的完整配置,包括摄取管道、索引和搜索管道。您可以通过选择右侧按钮以 JSON 或 YAML 格式下载模板。要在其他 OpenSearch 集群中构建相同的资源,请使用Provision Workflow API。
高级数据转换
ML 推理处理器提供了多种灵活的方式来将输入数据转换成模型输入以及从模型输出转换数据。
在 Inputs 中,您可以配置传递给模型的参数。共有四种输入参数转换类型:
- 数据字段:使用现有数据字段作为模型输入。
- JSONPath 表达式:从 JSON 结构中提取数据,并使用JSONPath将提取的数据映射到模型输入字段。
- Prompt:使用可以包含动态变量的常量值。这结合了
Custom string转换和Data field和JSONPath expression转换的元素,使其特别适用于为 LLM 构建提示。 - 自定义字符串:使用常量字符串值。
在 Outputs 中,您可以配置从模型传递的值。共有三种输出参数转换类型:
- 数据字段:将模型输出复制到新文档字段中。
- JSONPath 表达式:从 JSON 结构中提取数据,并使用JSONPath将提取的数据映射到一个或多个新文档字段。
- 无转换:不转换模型输出字段,保留其名称和值。
后续步骤
-
有关建议与 AI 搜索流一起使用的模型和模型接口,请参阅模型。
-
有关不同 AI/ML 用例的示例配置,请参阅配置 AI 搜索类型。