使用 AWS CloudFormation 和 Amazon Bedrock 进行语义搜索
本教程展示了如何使用 AWS CloudFormation 和 Amazon Bedrock 在 Amazon OpenSearch Service 中实现语义搜索。有关更多信息,请参阅语义搜索。
如果您使用的是自管 OpenSearch 而不是 Amazon OpenSearch Service,请使用蓝图为 Amazon Bedrock 模型创建连接器。有关创建连接器的更多信息,请参阅连接器。
CloudFormation 集成自动化了《使用 Amazon Bedrock Titan 进行语义搜索》教程中的步骤。CloudFormation 模板会创建一个 AWS Identity and Access Management (IAM) 角色,并调用一个 AWS Lambda 函数来设置 AI 连接器和模型。
将以 your_ 为前缀的占位符替换为您自己的值。
先决条件:创建 OpenSearch 集群
前往 Amazon OpenSearch Service 控制台并创建一个 OpenSearch 域。
记下域 Amazon Resource Name (ARN);您将在后续步骤中使用它。
步骤 1:映射后端角色
OpenSearch CloudFormation 模板使用 Lambda 函数创建一个带有 IAM 角色的 AI 连接器。您必须将 IAM 角色映射到 ml_full_access 以授予所需权限。请遵循《使用 Amazon Bedrock Titan 进行语义搜索教程》中的步骤 2.2 来映射后端角色。
IAM 角色在 CloudFormation 模板的 Lambda Invoke OpenSearch ML Commons Role Name 字段中指定。默认的 IAM 角色是 LambdaInvokeOpenSearchMLCommonsRole,因此您必须将后端角色 arn:aws:iam::your_aws_account_id:role/LambdaInvokeOpenSearchMLCommonsRole 映射到 ml_full_access。
对于更广泛的映射,您可以使用通配符授予所有角色 ml_full_access。
arn:aws:iam::your_aws_account_id:role/*
由于 all_access 包含比 ml_full_access 更多的权限,因此将后端角色映射到 all_access 也是可接受的。
步骤 2:运行 CloudFormation 模板
CloudFormation 模板集成可在 Amazon OpenSearch Service 控制台中找到。从左侧导航窗格中,选择集成,如下图所示。
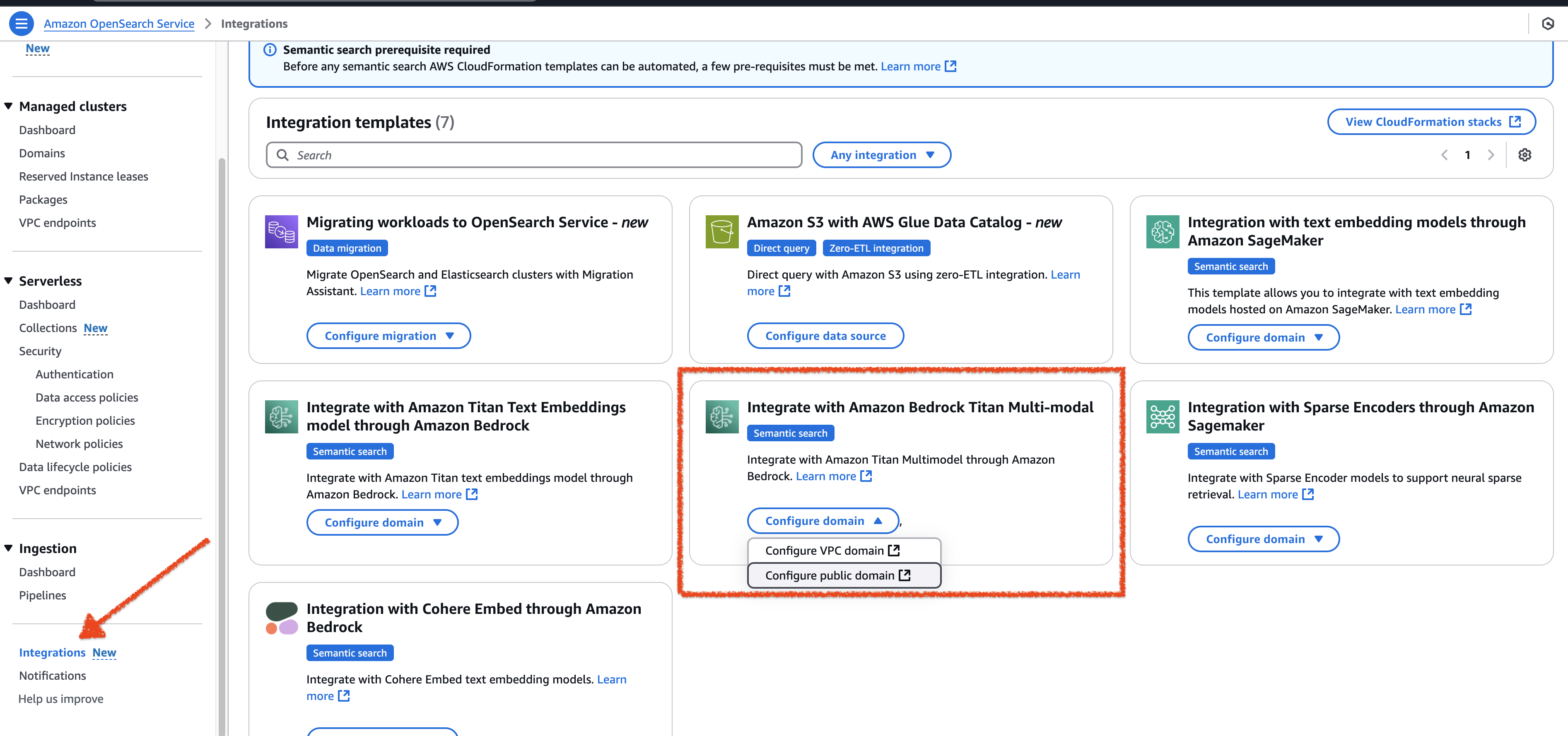
要创建连接器,请填写以下表单。
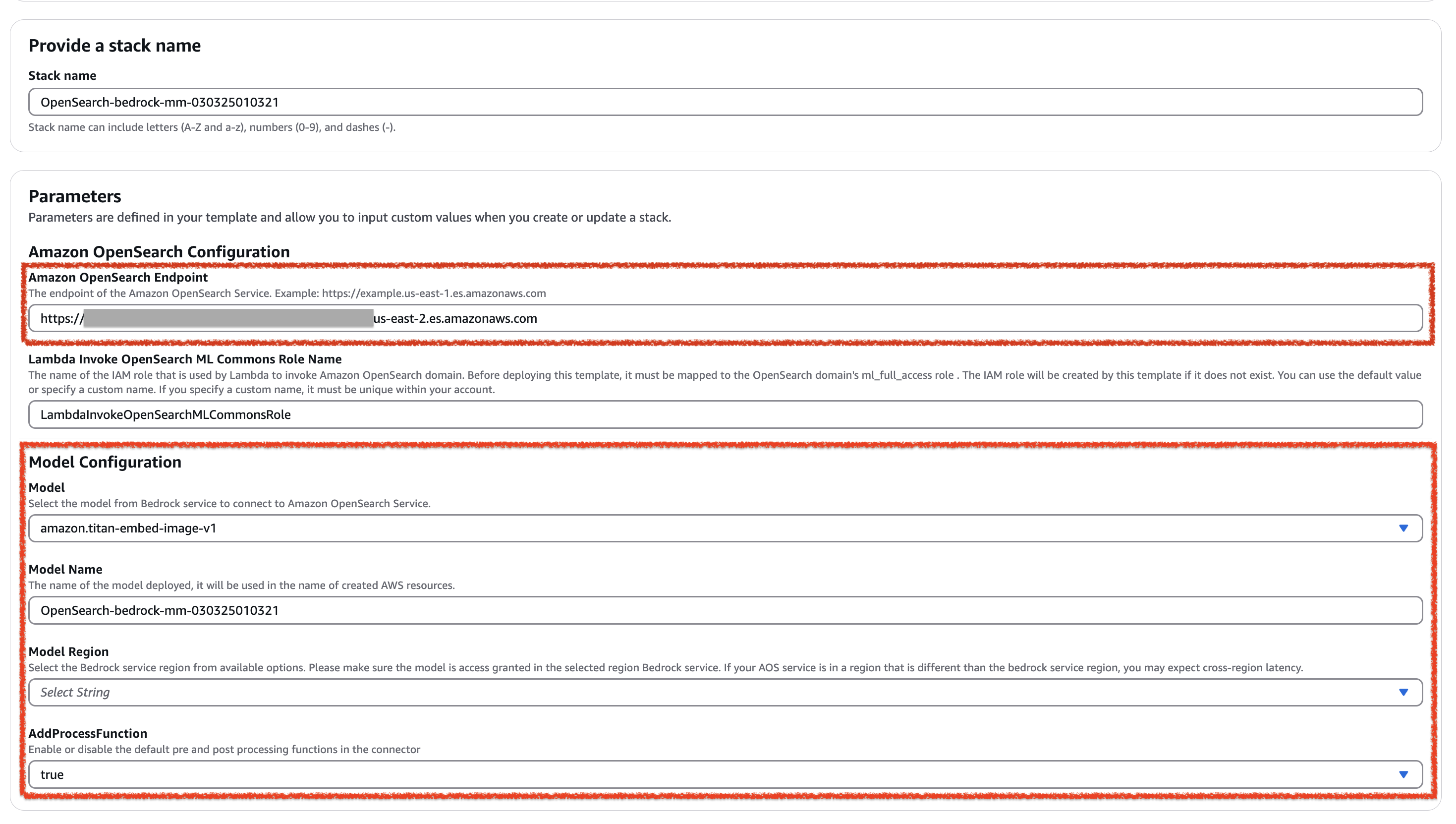
填写以下字段,其他字段保持默认值。
- 输入您的 Amazon OpenSearch 端点。
- 在模型配置中,选择要部署的模型。选择以下受支持的模型之一:
amazon.titan-embed-text-v1amazon.titan-embed-image-v1amazon.titan-embed-text-v2:0cohere.embed-english-v3cohere.embed-multilingual-v3
- 选择模型区域(这是 Amazon Bedrock 区域)。
- 在 AddProcessFunction 中,选择
true启用或false禁用连接器中的默认预处理和后处理函数。
输出
部署后,您可以在 CloudFormation 堆栈输出中找到 ConnectorId、ModelId 和 BedrockEndpoint。
如果发生错误,请按照以下步骤查看日志:
- 导航到 CloudWatch Logs 部分。
- 搜索包含(或关联有)您的 CloudFormation 堆栈名称的日志组。
步骤 3:配置语义搜索
按照以下步骤配置语义搜索。
步骤 3.1:创建摄取管道
首先,创建一个摄取管道,该管道使用 Amazon Bedrock 上的模型从输入文本创建嵌入。
PUT /_ingest/pipeline/my_bedrock_embedding_pipeline
{
"description": "text embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": "your_bedrock_embedding_model_id_created_in_step3",
"field_map": {
"text": "text_knn"
}
}
}
]
}
步骤 3.2:创建向量索引
接下来,创建一个用于存储输入文本和生成嵌入的向量索引
PUT my_index
{
"settings": {
"index": {
"knn.space_type": "cosinesimil",
"default_pipeline": "my_bedrock_embedding_pipeline",
"knn": "true"
}
},
"mappings": {
"properties": {
"text_knn": {
"type": "knn_vector",
"dimension": 1536
}
}
}
}
步骤 3.3:摄取数据
将示例文档摄取到索引中
POST /my_index/_doc/1000001
{
"text": "hello world."
}
步骤 3.4:搜索索引
运行向量搜索以从向量索引中检索文档
POST /my_index/_search
{
"query": {
"neural": {
"text_knn": {
"query_text": "hello",
"model_id": "your_embedding_model_id_created_in_step4",
"k": 100
}
}
},
"size": "1",
"_source": ["text"]
}