使用 Amazon Bedrock Titan 的语义搜索
本教程将向您展示如何使用 Amazon Bedrock Titan 嵌入模型在 Amazon OpenSearch Service 中实现语义搜索。有关更多信息,请参阅语义搜索。
如果使用 Python,您可以使用 opensearch-py-ml 客户端 CLI 创建 Amazon Bedrock Titan 嵌入连接器并测试模型。CLI 自动化了许多配置步骤,从而加快了设置速度并减少了出错的可能性。有关使用 CLI 的更多信息,请参阅 CLI 文档。
如果使用自管 OpenSearch 而不是 Amazon OpenSearch Service,请使用 蓝图 创建到 Amazon Bedrock 上模型的连接器。有关创建连接器的更多信息,请参阅 连接器。
在 Amazon OpenSearch Service 中设置嵌入模型最简单的方法是使用 AWS CloudFormation。或者,您可以使用 AIConnectorHelper notebook 设置嵌入模型。
Amazon Bedrock 有一个 配额限制。有关增加此限制的更多信息,请参阅 通过 Amazon Bedrock 中的预置吞吐量提高模型调用容量。
将以 your_ 为前缀的占位符替换为您自己的值。
先决条件:创建 OpenSearch 集群
转到 Amazon OpenSearch Service 控制台并创建 OpenSearch 域。
记下域的 Amazon 资源名称 (ARN);您将在后续步骤中使用它。
步骤 1:创建 IAM 角色以调用 Amazon Bedrock 上的模型
要调用 Amazon Bedrock 上的模型,您必须创建具有适当权限的 AWS Identity and Access Management (IAM) 角色。连接器将使用此角色调用模型。
转到 IAM 控制台,创建名为 my_invoke_bedrock_role 的新 IAM 角色,并添加以下信任策略和权限
- 自定义信任策略
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- 权限
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"bedrock:InvokeModel"
],
"Effect": "Allow",
"Resource": "arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1"
}
]
}
记下角色 ARN;您将在后续步骤中使用它。
步骤 2:在 OpenSearch 中配置 IAM 角色
按照以下步骤在 Amazon OpenSearch Service 中配置 IAM 角色。
步骤 2.1:创建用于签署连接器请求的 IAM 角色
生成一个新的 IAM 角色,专门用于签署您的创建连接器 API 请求。
创建名为 my_create_bedrock_connector_role 的 IAM 角色,并添加以下信任策略和权限
- 自定义信任策略
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "your_iam_user_arn"
},
"Action": "sts:AssumeRole"
}
]
}
您将在步骤 3.1 中使用 your_iam_user_arn IAM 用户来承担此角色。
- 权限
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "your_iam_role_arn_created_in_step1"
},
{
"Effect": "Allow",
"Action": "es:ESHttpPost",
"Resource": "your_opensearch_domain_arn_created"
}
]
}
记下此角色 ARN;您将在后续步骤中使用它。
步骤 2.2:映射后端角色
按照以下步骤映射后端角色
- 登录 OpenSearch Dashboards,然后在顶部菜单中选择 Security(安全)。
- 选择 Roles(角色),然后选择 ml_full_access 角色。
- 在 ml_full_access 角色详细信息页面上,选择 Mapped users(已映射用户),然后选择 Manage mapping(管理映射)。
- 在 Backend roles(后端角色)字段中输入在步骤 2.1 中创建的 IAM 角色 ARN,如下图所示。
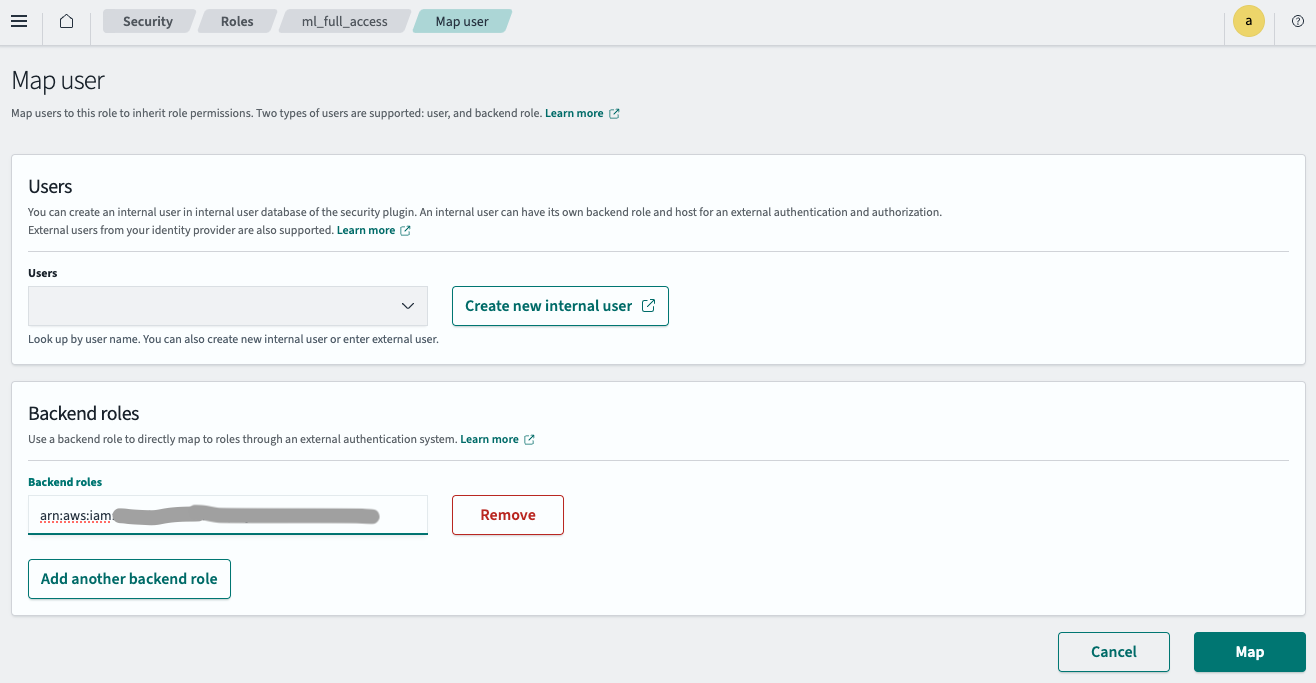
- 选择 Map(映射)。
IAM 角色现已成功配置到您的 OpenSearch 集群中。
步骤 3:创建连接器
按照以下步骤为模型创建连接器。有关创建连接器的更多信息,请参阅 连接器。
步骤 3.1:获取临时凭证
使用步骤 2.1 中指定的 IAM 用户的凭证来承担角色
aws sts assume-role --role-arn your_iam_role_arn_created_in_step2.1 --role-session-name your_session_name
从响应中复制临时凭证,并将其配置到 ~/.aws/credentials 中
[default]
AWS_ACCESS_KEY_ID=your_access_key_of_role_created_in_step2.1
AWS_SECRET_ACCESS_KEY=your_secret_key_of_role_created_in_step2.1
AWS_SESSION_TOKEN=your_session_token_of_role_created_in_step2.1
步骤 3.2:创建连接器
使用配置在 ~/.aws/credentials 中的临时凭证运行以下 Python 代码
import boto3
import requests
from requests_aws4auth import AWS4Auth
host = 'your_amazon_opensearch_domain_endpoint_created'
region = 'your_amazon_opensearch_domain_region'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
path = '/_plugins/_ml/connectors/_create'
url = host + path
payload = {
"name": "Amazon Bedrock Connector: titan embedding v1",
"description": "The connector to bedrock Titan embedding model",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "your_bedrock_model_region",
"service_name": "bedrock"
},
"credential": {
"roleArn": "your_iam_role_arn_created_in_step1"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://bedrock-runtime.your_bedrock_model_region.amazonaws.com/model/amazon.titan-embed-text-v1/invoke",
"headers": {
"content-type": "application/json",
"x-amz-content-sha256": "required"
},
"request_body": "{ \"inputText\": \"${parameters.inputText}\" }",
"pre_process_function": "\n StringBuilder builder = new StringBuilder();\n builder.append(\"\\\"\");\n String first = params.text_docs[0];\n builder.append(first);\n builder.append(\"\\\"\");\n def parameters = \"{\" +\"\\\"inputText\\\":\" + builder + \"}\";\n return \"{\" +\"\\\"parameters\\\":\" + parameters + \"}\";",
"post_process_function": "\n def name = \"sentence_embedding\";\n def dataType = \"FLOAT32\";\n if (params.embedding == null || params.embedding.length == 0) {\n return params.message;\n }\n def shape = [params.embedding.length];\n def json = \"{\" +\n \"\\\"name\\\":\\\"\" + name + \"\\\",\" +\n \"\\\"data_type\\\":\\\"\" + dataType + \"\\\",\" +\n \"\\\"shape\\\":\" + shape + \",\" +\n \"\\\"data\\\":\" + params.embedding +\n \"}\";\n return json;\n "
}
]
}
headers = {"Content-Type": "application/json"}
r = requests.post(url, auth=awsauth, json=payload, headers=headers)
print(r.text)
脚本输出连接器 ID
{"connector_id":"1p0u8o0BWbTmLN9F2Y7m"}
记下连接器 ID;您将在下一步中使用它。
步骤 4:创建并测试模型
登录 OpenSearch Dashboards,打开 DevTools 控制台,并运行以下请求来创建和测试模型。
-
创建模型组
POST /_plugins/_ml/model_groups/_register { "name": "Bedrock_embedding_model", "description": "Test model group for bedrock embedding model" }响应包含模型组 ID
{ "model_group_id": "LxWiQY0BTaDH9c7t9xeE", "status": "CREATED" } -
注册模型
POST /_plugins/_ml/models/_register { "name": "bedrock titan embedding model v1", "function_name": "remote", "description": "test embedding model", "model_group_id": "LxWiQY0BTaDH9c7t9xeE", "connector_id": "N0qpQY0BOhavBOmfOCnw" }响应包含模型 ID
{ "task_id": "O0q3QY0BOhavBOmf1SmL", "status": "CREATED", "model_id": "PEq3QY0BOhavBOmf1Sml" } -
部署模型
POST /_plugins/_ml/models/PEq3QY0BOhavBOmf1Sml/_deploy响应包含部署操作的任务 ID
{ "task_id": "PUq4QY0BOhavBOmfBCkQ", "task_type": "DEPLOY_MODEL", "status": "COMPLETED" } -
测试模型
POST /_plugins/_ml/models/PEq3QY0BOhavBOmf1Sml/_predict { "parameters": { "inputText": "hello world" } }响应包含模型生成的嵌入
{ "inference_results": [ { "output": [ { "name": "sentence_embedding", "data_type": "FLOAT32", "shape": [ 1536 ], "data": [ 0.7265625, -0.0703125, 0.34765625, ...] } ], "status_code": 200 } ] }
步骤 5:配置语义搜索
按照以下步骤配置语义搜索。
步骤 5.1:创建摄取管道
首先,创建一个摄取管道,该管道使用 Amazon SageMaker 中的模型从输入文本创建嵌入
PUT /_ingest/pipeline/my_bedrock_embedding_pipeline
{
"description": "text embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": "your_bedrock_embedding_model_id_created_in_step4",
"field_map": {
"text": "text_knn"
}
}
}
]
}
步骤 5.2:创建向量索引
接下来,创建一个向量索引来存储输入文本和生成的嵌入
PUT my_index
{
"settings": {
"index": {
"knn.space_type": "cosinesimil",
"default_pipeline": "my_bedrock_embedding_pipeline",
"knn": "true"
}
},
"mappings": {
"properties": {
"text_knn": {
"type": "knn_vector",
"dimension": 1536
}
}
}
}
步骤 5.3:摄取数据
将示例文档摄取到索引中
POST /my_index/_doc/1000001
{
"text": "hello world."
}
步骤 5.4:搜索索引
运行向量搜索以从向量索引中检索文档
POST /my_index/_search
{
"query": {
"neural": {
"text_knn": {
"query_text": "hello",
"model_id": "your_embedding_model_id_created_in_step4",
"k": 100
}
}
},
"size": "1",
"_source": ["text"]
}