星型树索引
星型树索引是一种专门的索引结构,旨在通过预先计算和存储不同粒度级别的聚合值来提高聚合性能。这种索引技术可以加速聚合执行,特别是对于多字段聚合。
一旦启用星型树索引,如果筛选字段与定义维度匹配,并且聚合字段与星型树映射配置中定义的度量匹配,OpenSearch 将自动构建和使用星型树索引来优化支持的聚合。无需更改查询语法或请求参数。
当您想要加速聚合时,使用星型树索引。
- 星型树索引原生支持多字段聚合。
- 星型树索引是在索引过程中实时创建的,因此星型树中的数据始终是最新的。
- 星型树索引聚合数据以提高分页效率并减少搜索查询期间的磁盘 I/O。
星型树索引结构
星型树索引组织和聚合维度字段组合中的数据,并在摄取期间每次段刷新或更新时预先计算所有维度组合的度量值。这种结构使 OpenSearch 能够快速处理聚合查询,而无需扫描每个文档。
以下是星型树配置示例:
"ordered_dimensions": [
{
"name": "status"
},
{
"name": "port"
}
],
"metrics": [
{
"name": "size",
"stats": [
"sum"
]
},
{
"name": "latency",
"stats": [
"avg"
]
}
]
此配置定义了以下内容:
- 两个维度字段:
status和port。ordered_dimension字段指定数据如何排序(首先按status,然后按port)。 - 两个度量字段:
size和latency及其对应的聚合(sum和avg)。对于每个唯一的维度组合,度量值(Sum(size)和Avg(latency))都被预先聚合并存储在星型树结构中。
OpenSearch 根据此配置创建星型树索引结构。树中的每个节点都对应一个维度值(或通配符 *)。在查询时,OpenSearch 根据查询中提供的维度值遍历树。
叶节点
叶节点包含特定维度组合的预计算度量聚合。这些值作为文档值存储,并由星型树节点引用。
max_leaf_docs 设置控制每个叶节点可以引用的文档数量,这通过限制给定节点扫描的文档数量来帮助保持查询延迟可预测。
星节点
星节点(在下图中标记为 *)聚合特定维度的所有值。如果查询未指定该维度的过滤器,OpenSearch 将从星节点检索预计算的聚合,而不是遍历多个叶节点。例如,如果查询根据 port 过滤但未根据 status 过滤,OpenSearch 可以使用聚合所有状态值的星节点。
查询如何使用星型树
下图显示了为此示例创建的星型树索引和三个示例查询路径。在图中,请注意每个分支都对应一个维度(status 和 port)。某些节点包含预计算的聚合值(例如,Sum(size)),这允许 OpenSearch 在查询时跳过不必要的计算。
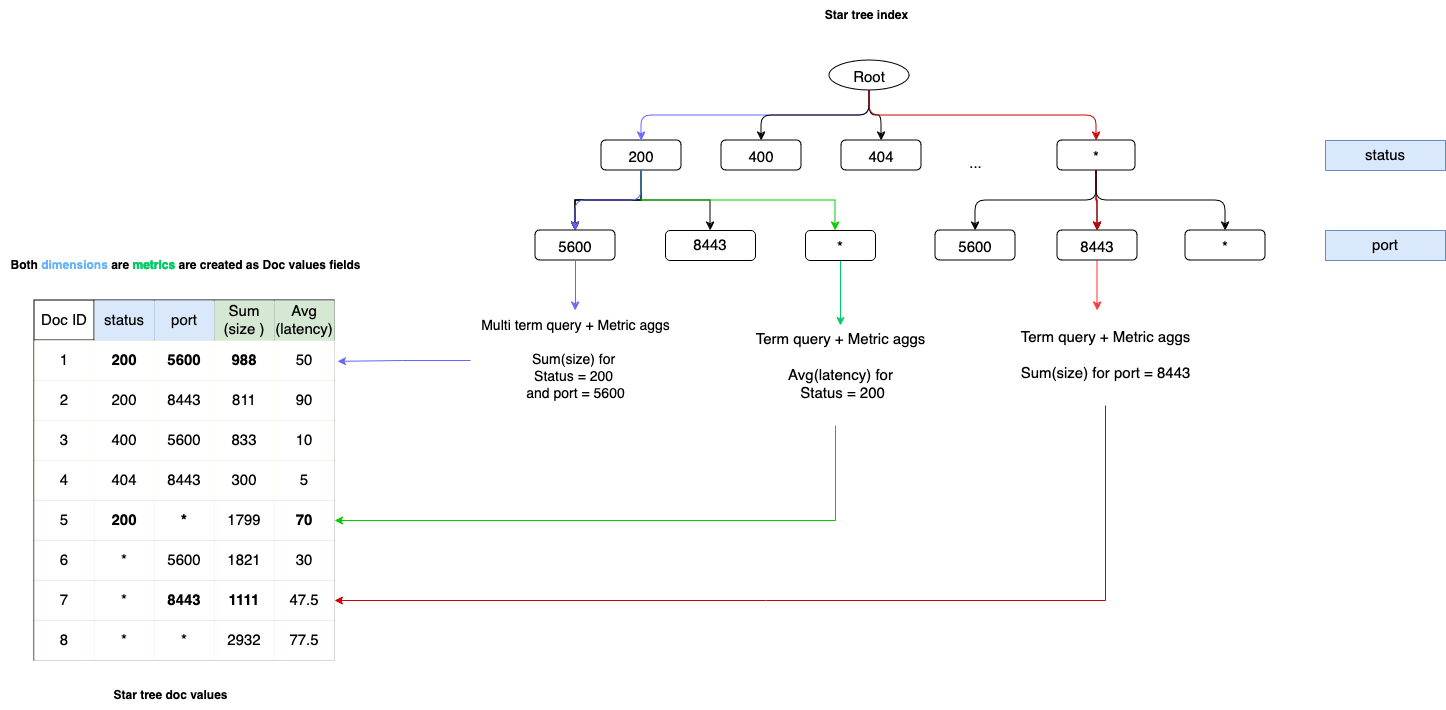
彩色箭头显示了三个查询示例:
-
蓝色箭头:带度量聚合的多术语查询。该查询同时根据
status = 200和port = 5600进行过滤,并计算请求大小的总和。- OpenSearch 遵循此路径:
根 → 200 → 5600 - 它从文档 ID 1 中检索度量,其中
Sum(size) = 988
- OpenSearch 遵循此路径:
-
绿色箭头:带度量聚合的单术语查询。该查询仅根据
status = 200进行过滤,并计算平均请求延迟。- OpenSearch 遵循此路径:
根 → 200 → * - 它从文档 ID 5 中检索度量,其中
Avg(latency) = 70
- OpenSearch 遵循此路径:
-
红色箭头:带度量聚合的单术语查询。该查询仅根据
port = 8443进行过滤,并计算请求大小的总和。- OpenSearch 遵循此路径:
根 → * → 8443 - 它从文档 ID 7 中检索度量,其中
Sum(size) = 1111
- OpenSearch 遵循此路径:
这些示例展示了 OpenSearch 如何选择星型树中的最短路径并使用预聚合值来高效处理查询。
限制
请注意星型树索引的以下限制:
- 星型树索引不支持更新或删除。要使用星型树索引,数据应为仅追加。请参阅启用星型树索引。
- 星型树索引仅适用于根据索引的星型树配置中定义的维度字段进行过滤和聚合度量字段的聚合查询。
- 对星型树配置的任何更改都需要重新索引。
- 不支持数组值。
- 仅支持特定查询和聚合。
- 避免使用
_id等高基数字段作为维度,因为它们会显著增加存储使用和查询延迟。
启用星型树索引
星型树索引行为由以下集群级别和索引级别设置控制。索引级别设置优先于集群设置。
| 设置 | 范围 | 默认值 | 目的 |
|---|---|---|---|
indices.composite_index.star_tree.enabled | 集群 | true | 启用或禁用集群范围的星型树搜索优化。 |
index.composite_index | 索引 | 无 | 启用特定索引的星型树索引。必须在创建索引时设置。 |
index.append_only.enabled | 索引 | 无 | 星型树索引的必需项。阻止更新和删除。必须为 true。 |
index.search.star_tree_index.enabled | 索引 | true | 启用或禁用对索引的搜索查询使用星型树索引。 |
将 indices.composite_index.star_tree.enabled 设置为 false 会阻止 OpenSearch 在搜索期间使用星型树优化,但星型树索引结构仍会创建。要完全删除星型树结构,您必须在没有星型树映射的情况下重新索引数据。
要创建使用星型树索引的索引,请发送以下请求:
PUT /logs
{
"settings": {
"index.composite_index": true,
"index.append_only.enabled": true
}
}
确保在星型树映射中使用的维度和度量字段的 doc_values 参数已启用。对于大多数字段类型,此参数默认启用。有关更多信息,请参阅文档值。
禁用星型树使用
默认情况下,indices.composite_index.star_tree.enabled 集群设置和 index.search.star_tree_index.enabled 索引设置都设置为 true。要禁用使用星型树索引进行搜索,请将这两个设置都设置为 false。请注意,索引设置优先于集群设置。
映射示例
以下示例展示了如何创建一个星型树索引,用于预先计算 logs 索引中的聚合。对于维度字段中所有值的组合,size 和 latency 字段上分别计算 sum 和 average 聚合。维度按 status、port 和 method 的顺序排列,这决定了数据在树结构中的组织方式。
PUT /logs
{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 0,
"index.composite_index": true,
"index.append_only.enabled": true
},
"mappings": {
"composite": {
"request_aggs": {
"type": "star_tree",
"config": {
"date_dimension" : {
"name": "@timestamp",
"calendar_intervals": [
"month",
"day"
]
},
"ordered_dimensions": [
{
"name": "status"
},
{
"name": "port"
},
{
"name": "method"
}
],
"metrics": [
{
"name": "size",
"stats": [
"sum"
]
},
{
"name": "latency",
"stats": [
"avg"
]
}
]
}
}
},
"properties": {
"status": {
"type": "integer"
},
"port": {
"type": "integer"
},
"size": {
"type": "integer"
},
"method" : {
"type": "keyword"
},
"latency": {
"type": "scaled_float",
"scaling_factor": 10
}
}
}
}
有关星型树索引映射和参数的更多信息,请参阅星型树字段类型。
支持的查询和聚合
星型树索引优化聚合。每个查询都必须包含至少一个受支持的聚合才能使用星型树优化。
支持的查询
不带聚合的查询无法使用星型树优化。查询的字段必须存在于星型树配置的 ordered_dimensions 部分。支持以下查询:
布尔查询限制
星型树索引中的布尔查询遵循每种子句类型的特定规则:
must和filter子句- 两者都受支持并以相同方式处理,因为
filter不影响评分。 - 可以在不同维度上操作。
- 所有
must/filter子句(包括嵌套子句)中每个维度只允许一个条件。 - 支持术语查询、多个术语查询和范围查询。
- 两者都受支持并以相同方式处理,因为
should子句- 必须在同一维度上操作,并且不能在不同维度上操作
- 只能使用术语查询、多个术语查询和范围查询。
must子句内部的should子句- 充当必需条件。
- 当与外部
must在同一维度上操作时:should条件的并集与外部must条件进行交集。 - 当在不同维度上操作时:正常作为必需条件处理。
- 不支持
must_not子句。 - 不支持带有
minimum_should_match参数的查询。
以下布尔查询是受支持的,因为它遵循这些限制:
{
"bool": {
"must": [
{"term": {"method": "GET"}}
],
"filter": [
{"range": {"status": {"gte": 200, "lt": 300}}}
],
"should": [
{"term": {"port": 443}},
{"term": {"port": 8443}}
]
}
}
以下布尔查询不受支持,因为它们违反了这些限制:
{
"bool": {
"should": [
{"term": {"status": 200}},
{"term": {"method": "GET"}} // SHOULD across different dimensions
]
}
}
{
"bool": {
"must": [
{"term": {"status": 200}}
],
"must_not": [ // MUST_NOT not supported
{"term": {"method": "DELETE"}}
]
}
}
支持的聚合
星型树索引支持以下聚合。
度量聚合
支持以下度量聚合:
要将可搜索聚合与星型树索引一起使用,请确保满足以下先决条件:
- 字段必须存在于星型树配置的
metrics部分。 - 度量聚合类型必须是
stats参数的一部分。
以下示例使用示例映射获取所有错误日志中 status=500 的 size 字段值的总和:
POST /logs/_search
{
"query": {
"term": {
"status": "500"
}
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
使用星型树索引,结果将从单个聚合文档中检索,因为它遍历 status=500 节点,而不是扫描所有匹配的文档。这会降低查询延迟。
带度量聚合的日期直方图
您可以使用带有度量子聚合的日期直方图在日历间隔上。
要使用日期直方图聚合并使其在星型树索引中可搜索,请记住以下要求:
- 星型树映射配置中的日历间隔可以使用请求的日历字段或比请求字段粒度更低的字段。例如,如果聚合使用
month字段,则星型树搜索仍可以使用day等粒度更低的字段。 - 度量子聚合必须是聚合请求的一部分。
以下示例过滤日志,仅包含状态码在 200 到 400 之间的日志,并将响应的 size 设置为 0,以便仅返回聚合结果。然后按日历月聚合过滤后的日志,并计算每个月请求的 size 总和:
POST /logs/_search
{
"size": 0,
"query": {
"range": {
"status": {
"gte": "200",
"lte": "400"
}
}
},
"aggs": {
"by_month": {
"date_histogram": {
"field": "@timestamp",
"calendar_interval": "month"
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
}
}
关键字和数字术语聚合
您可以使用术语聚合在关键字和数字字段上进行星型树索引搜索。
对于与术语聚合兼容的星型树搜索,请记住以下行为:
- 术语聚合中使用的字段应是星型树索引中定义的维度的一部分。
- 度量子聚合是可选的,只要相关度量是星型树配置的一部分即可。
以下示例按 user_id 字段聚合日志,并返回每个唯一用户的计数:
POST /logs/_search
{
"size": 0,
"aggs": {
"users": {
"terms": {
"field": "user_id"
}
}
}
}
以下示例按 order_quantity 聚合订单,并计算每个数量的平均 total_price:
POST /orders/_search
{
"size": 0,
"aggs": {
"quantities": {
"terms": {
"field": "order_quantity"
},
"aggs": {
"avg_total_price": {
"avg": {
"field": "total_price"
}
}
}
}
}
}
范围聚合
您可以使用范围聚合在数字字段上进行星型树索引搜索。
要使范围聚合与星型树索引有效配合,请记住以下行为:
- 范围聚合中使用的字段应是星型树索引中定义的维度的一部分。
- 您可以包含度量子聚合以计算每个定义范围内的度量,只要相关度量是星型树配置的一部分即可。
以下示例根据 temperature 字段的预定义范围聚合文档:
POST /sensors/_search
{
"size": 0,
"aggs": {
"temperature_ranges": {
"range": {
"field": "temperature",
"ranges": [
{ "to": 20 },
{ "from": 20, "to": 30 },
{ "from": 30 }
]
}
}
}
}
以下示例按价格范围聚合销售数据,并计算每个范围内的总 quantity:
POST /sales/_search
{
"size": 0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 100 },
{ "from": 100, "to": 500 },
{ "from": 500 }
]
},
"aggs": {
"total_quantity": {
"sum": {
"field": "quantity"
}
}
}
}
}
}
嵌套聚合
您可以将多个受支持的桶聚合(例如 terms 和 range)组合成嵌套结构,星型树索引将优化这些嵌套聚合。有关嵌套聚合的更多信息,请参阅嵌套聚合。