预测入门
您可以通过在 OpenSearch Dashboards 导航面板中选择**预测**来定义和配置预测器。
步骤 1:定义预测器
一个**预测器**代表一个独立的预测任务。您可以创建多个预测器并行运行,每个预测器分析不同的数据源。按照以下步骤定义新的预测器:
-
在**预测器列表**视图中,选择**创建预测器**。
- 通过输入以下信息定义数据源:
- **名称** – 提供一个唯一且具有描述性的名称,例如
requests-10min。 - **描述** – 总结预测器的用途,例如
Forecast total request count every 10 minutes。 - **索引** – 选择一个或多个索引、索引模式或别名。通过跨集群搜索(
cluster-name:index-pattern)支持远程索引。欲了解更多信息,请参阅跨集群搜索。如果启用了安全插件,请参阅选择具有精细访问控制的远程索引。
- **名称** – 提供一个唯一且具有描述性的名称,例如
-
(可选)选择**添加数据过滤器**以设置**字段**、**操作符**和**值**,或选择**使用查询 DSL**来定义布尔查询。以下示例使用查询领域特定语言 (DSL) 过滤器来匹配三个 URL 路径:
{ "bool": { "should": [ { "term": { "urlPath.keyword": "/domain/{id}/short" } }, { "term": { "urlPath.keyword": "/sub_dir/{id}/short" } }, { "term": { "urlPath.keyword": "/abcd/123/{id}/xyz" } } ] } } -
在**时间戳字段**下,选择存储时间戳的字段。
-
在**指标(metric)**部分,为预测器添加一个指标。每个预测器支持一个指标以获得最佳准确性。选择以下选项之一:
- 选择预定义聚合函数:
average()、count()、sum()、min()或max()。 - 要使用自定义聚合,请在**基于预测**下选择**自定义表达式**,并定义您自己的查询 DSL 表达式。例如,以下查询预测具有特定账户类型的唯一账户数量:
{ "bbb_unique_accounts": { "filter": { "bool": { "must": [ { "wildcard": { "accountType": { "wildcard": "*blah*", "boost": 1 } } } ], "adjust_pure_negative": true, "boost": 1 } }, "aggregations": { "uniqueAccounts": { "cardinality": { "field": "account" } } } } } - 选择预定义聚合函数:
-
(可选)在**类别字段**部分,启用**使用类别字段拆分时间序列**,以在实体级别(例如,按 IP 地址、产品 ID 或国家代码)生成预测。
可以缓存到内存中的唯一实体数量是有限的。使用以下公式估算容量:
(data nodes × heap size × plugins.forecast.model_max_size_percent) ────────────────────────────────────────────────────────────────── entity-model size (MB)例如,一个具有 3 个数据节点、每个节点具有 8 GB JVM 堆内存和默认 10% 模型内存的集群,将包含以下数量的实体:
(8096 MB × 0.10 ÷ 1 MB) × 3 nodes ≈ 2429 entities要确定实体模型大小,请使用预测器配置文件 API。您可以使用
plugins.forecast.model_max_size_percent设置来提高或降低内存上限。
预测器会根据可用内存缓存最频繁和最近观察到的实体模型。不常见实体的模型在每个间隔期间会尽力从索引中加载,但不提供服务水平协议(SLA)保证。请务必根据代表性工作负载验证内存使用情况。
欲了解更多信息,请参阅博客文章改进异常检测:一分钟内一百万实体。尽管该文章侧重于异常检测,但其建议同样适用于预测,因为这两个功能共享相同的底层随机森林(RCF)模型。
步骤 2:添加模型参数
OpenSearch Dashboards 中的**建议参数**按钮会启动对近期历史记录的审查,以推荐合理的默认值。您可以通过调整以下参数来覆盖这些默认值:
- **预测间隔** – 指定聚合桶(例如,10 分钟)。较长的间隔可以平滑噪声并降低计算成本,但会延迟检测。较短的间隔可以更快地检测到变化,但会增加资源使用并可能引入噪声。选择能够产生稳定信号的最短间隔。
- **窗口延迟** – 告诉预测器事件发生和摄入之间预期会有多大的延迟。此延迟会向后调整预测间隔,以确保完整的数据覆盖。例如,如果预测间隔为 10 分钟,摄入延迟为 1 分钟,则将窗口延迟设置为 1 分钟可确保预测器评估 1:49 到 1:59 的数据,而不是 1:50 到 2:00 的数据。
- 为避免数据丢失,请将窗口延迟设置为预期摄入延迟的上限。但是,较长的延迟会降低预测的实时响应能力。
- **预测范围(Horizon)** – 指定要预测的未来桶数量。预测准确性会随着距离的增加而下降,因此只需选择具有实际操作意义的预测窗口。
- **历史数据** – 设置用于训练初始(冷启动)模型的历史数据点数量。最大值为 10,000。更多的历史数据可以在该限制范围内提高初始模型的准确性。
**高级**面板默认是折叠的,大多数用户可以直接使用建议的参数。如果您展开面板,可以微调三个额外参数:分片大小(shingle size)、建议的季节性(suggested seasonality)和近期强调(recency emphasis)。这些参数控制预测器如何在近期波动与长期模式之间取得平衡。
除非您的数据或用例有特殊要求,否则默认值——**分片大小 8**、**无明确季节性**和**近期强调 2560**——都是可靠的起点。
选择分片大小
将**分片大小**字段留空以使用自动启发式算法:
- 从默认值 8 开始。
- 如果定义了**建议的季节性**且其值大于 16,则将其替换为季节长度的一半。
- 如果定义了**预测范围**,并且其值的三分之一大于当前候选值,则相应地更新它。
最终值是这三个值的最大值:max(8, seasonality ÷ 2, horizon ÷ 3)
如果您提供自定义值,它将覆盖此计算结果。
确定存储量
默认情况下,预测结果存储在 opensearch-forecast-results 索引别名中。您可以:
- 构建仪表板和可视化。
- 将结果连接到警报插件。
- 像查询任何其他 OpenSearch 索引一样查询结果。
为了管理存储,插件会应用一个滚动策略:
- **滚动触发器** – 当主分片达到约 65 GB 时,将创建一个新的后端索引并更新别名。
- **保留** – 滚动的索引将至少保留 30 天,然后才会被删除。
您可以使用以下设置自定义此行为。
| 设置 | 描述 | 默认值 |
|---|---|---|
| 在触发滚动之前,每个分片允许的最大 Lucene 文档数量。一个结果大约是 4 个文档,每个文档约 47 字节,总计约 65 GB。 | 1_350_000_000 |
| 保留预测结果的时长。支持的持续时间格式例如 7d、90d。 | 30d |
指定自定义结果索引
您可以通过选择**自定义索引**并提供一个别名,例如 abc,将预测结果存储在自定义索引中。插件会创建一个类似于 opensearch-forecast-result-abc 的别名,指向后端索引(例如,opensearch-forecast-result-abc-history-2024.06.12-000002)。
要管理权限,请使用带连字符的命名空间。例如,将 opensearch-forecast-result-financial-us-* 分配给 financial 部门的 us 组的角色。{: .note } 如果启用了安全插件,请确保配置了适当的权限。
扁平化嵌套字段
如果您的自定义结果索引的文档包含嵌套字段,请启用**扁平化自定义结果索引**以简化聚合和可视化。
这将创建一个以自定义索引和预测器名称为前缀的独立索引(例如,opensearch-forecast-result-abc-flattened-test),并使用Painless 脚本附加一个摄入管道来扁平化嵌套数据。
如果您稍后禁用此选项,相关的摄入管道将被移除。
使用索引状态管理来管理扁平化结果索引的滚动和删除。
自定义结果索引生命周期管理
当满足以下任何条件时,插件会触发自定义结果索引的滚动:
| 参数 | 描述 | 类型 | 单位 | 默认值 | 必需 |
|---|---|---|---|---|---|
| 触发滚动所需的最小主分片总大小。 | 整数 | MB | 51200 (50 GB) | 否 |
| 触发滚动所需的最小索引年龄。 | 整数 | 天 | 7 | 否 |
| 在滚动索引被删除之前的最短时间量 | 整数 | 天 | 60 | 否 |
步骤 3:测试您的预测器
回溯测试是评估和优化关键预测设置(例如**间隔**和**预测范围**)的最快方法。在回溯测试期间,模型会在历史数据上进行训练,生成预测,并将其与实际值一起绘制,以帮助可视化预测准确性。如果结果不符合预期,您可以调整设置并重新运行测试。
回溯测试使用以下方法:
-
**训练窗口**:模型在由**历史数据**设置定义的历史数据上进行训练。
-
**滚动预测**:模型在时间序列中前进,重复执行以下操作:
- 摄入下一个实际数据点
- 在每一步发出预测
由于这是一种回顾性模拟,预测值会绘制在其原始时间戳上,让您可以看到模型在实时情况下的表现如何。
开始回溯测试
要开始测试:
- 滚动到**添加模型参数**页面底部。
- 选择**创建并测试**。
要跳过测试并立即创建预测器,请选择**创建**。
回溯测试通常需要 1 或 2 分钟,但运行时间取决于以下因素。
| 因素 | 重要原因 |
|---|---|
| 历史数据长度 | 更多历史数据会增加训练时间。 |
| 数据密度 | 密集数据会减慢聚合速度。 |
| 类别字段 | 模型为每个实体单独训练。 |
| 预测范围 | 更长的预测范围会增加生成的预测数量。 |
如果图表为空,如下图所示,请检查您的索引在所选间隔内是否至少包含一个具有 40 个以上数据点的时间序列。
解读图表
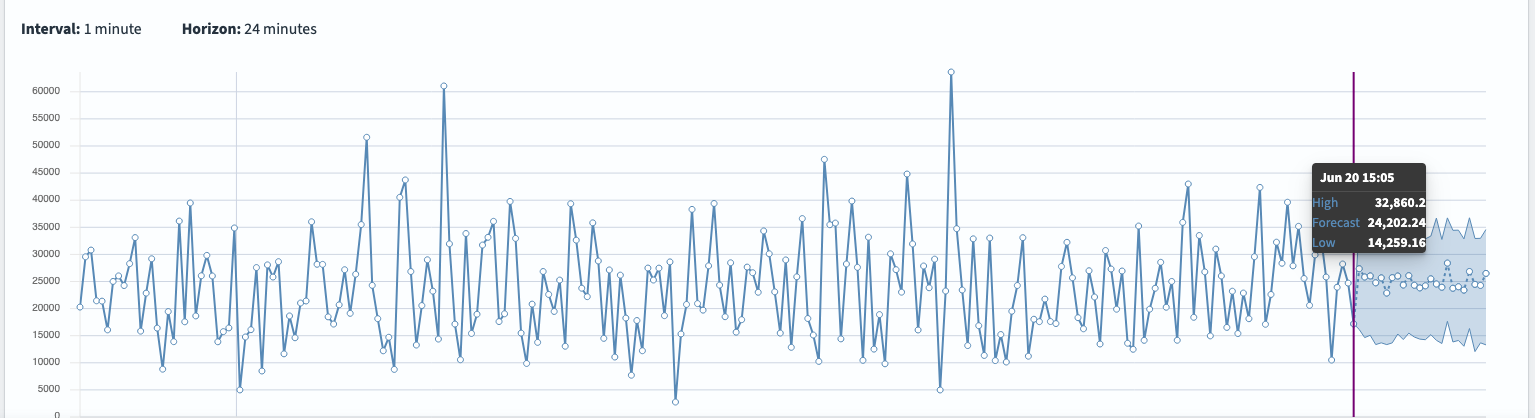
测试成功后,将鼠标悬停在图表上的任意点,即可查看确切值和置信区间:
- **实际数据** – 实线
- **中位数预测 (P50)** – 虚线
- **置信区间** – P10 和 P90 之间的阴影区域
下图显示了图表视图。
查看特定日期的预测
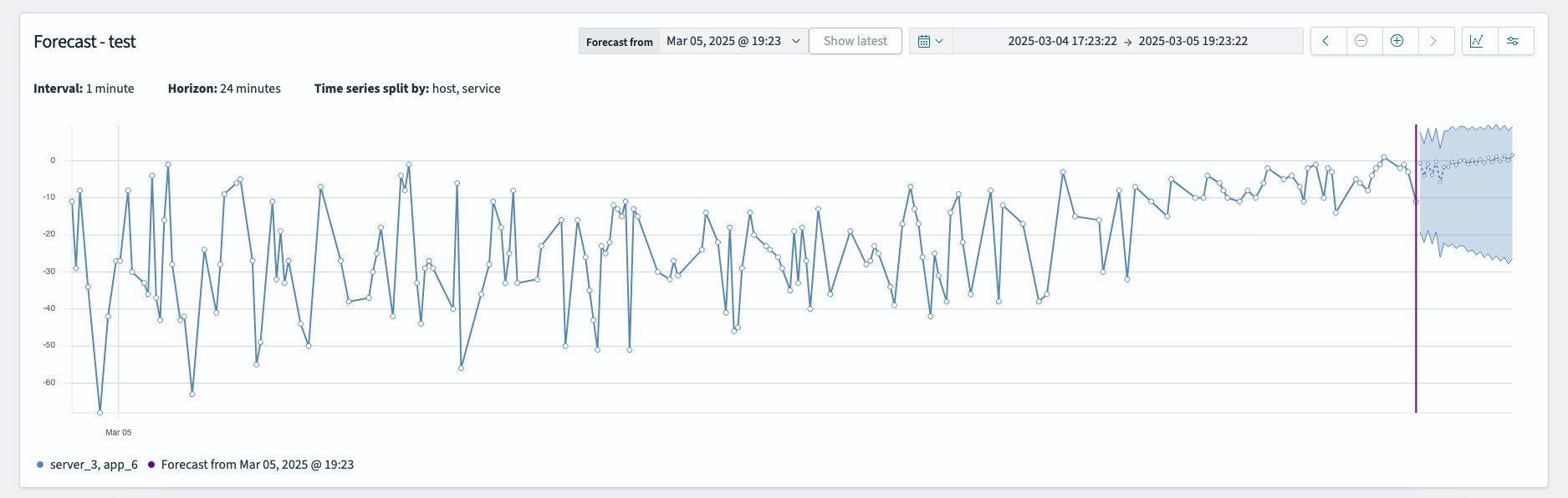
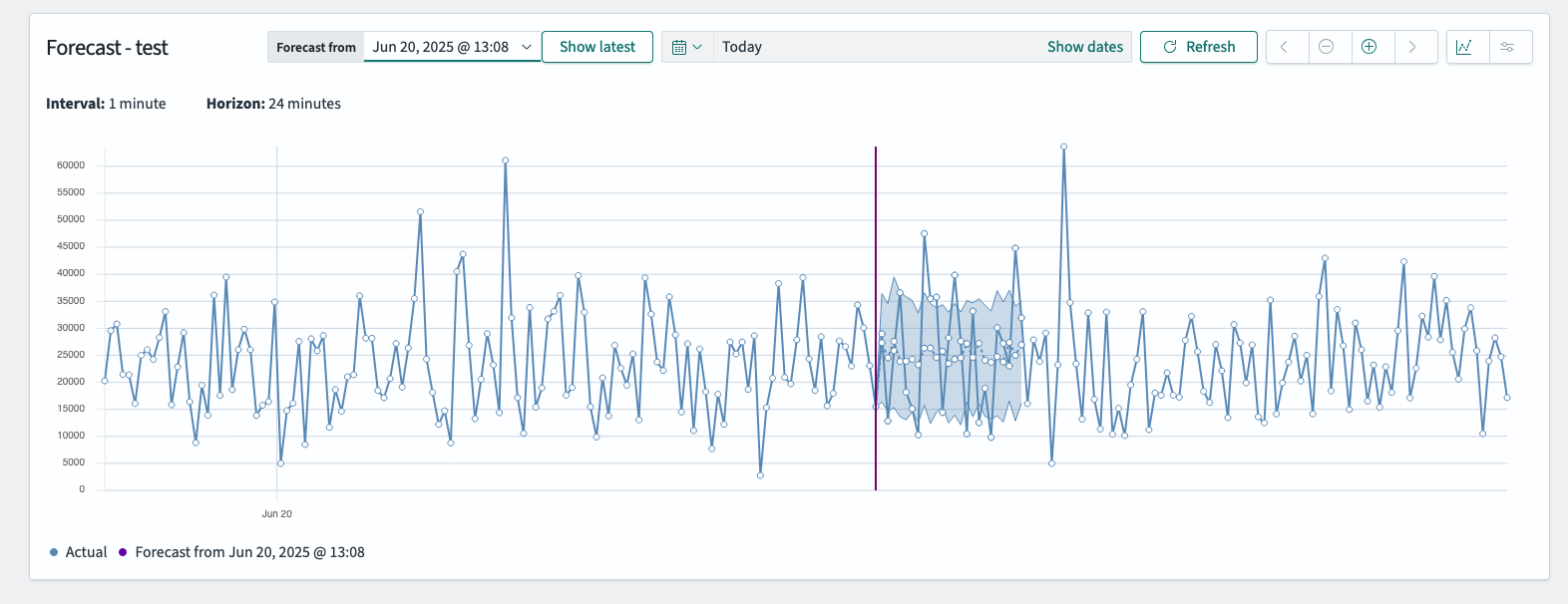
预测图表显示从最后一个实际数据点到配置的预测范围结束的预测。
例如,您可以在**从以下日期预测**字段中配置以下设置:
- **最后实际时间戳**:2025 年 3 月 5 日,19:23
- **间隔**:1 分钟
- 预测范围: 24
通过这些设置,预测范围将涵盖 2025 年 3 月 5 日,19:23 – 19:47,如下图所示。
您还可以使用**从以下日期预测**下拉列表来查看早期测试运行的预测,如下图所示。
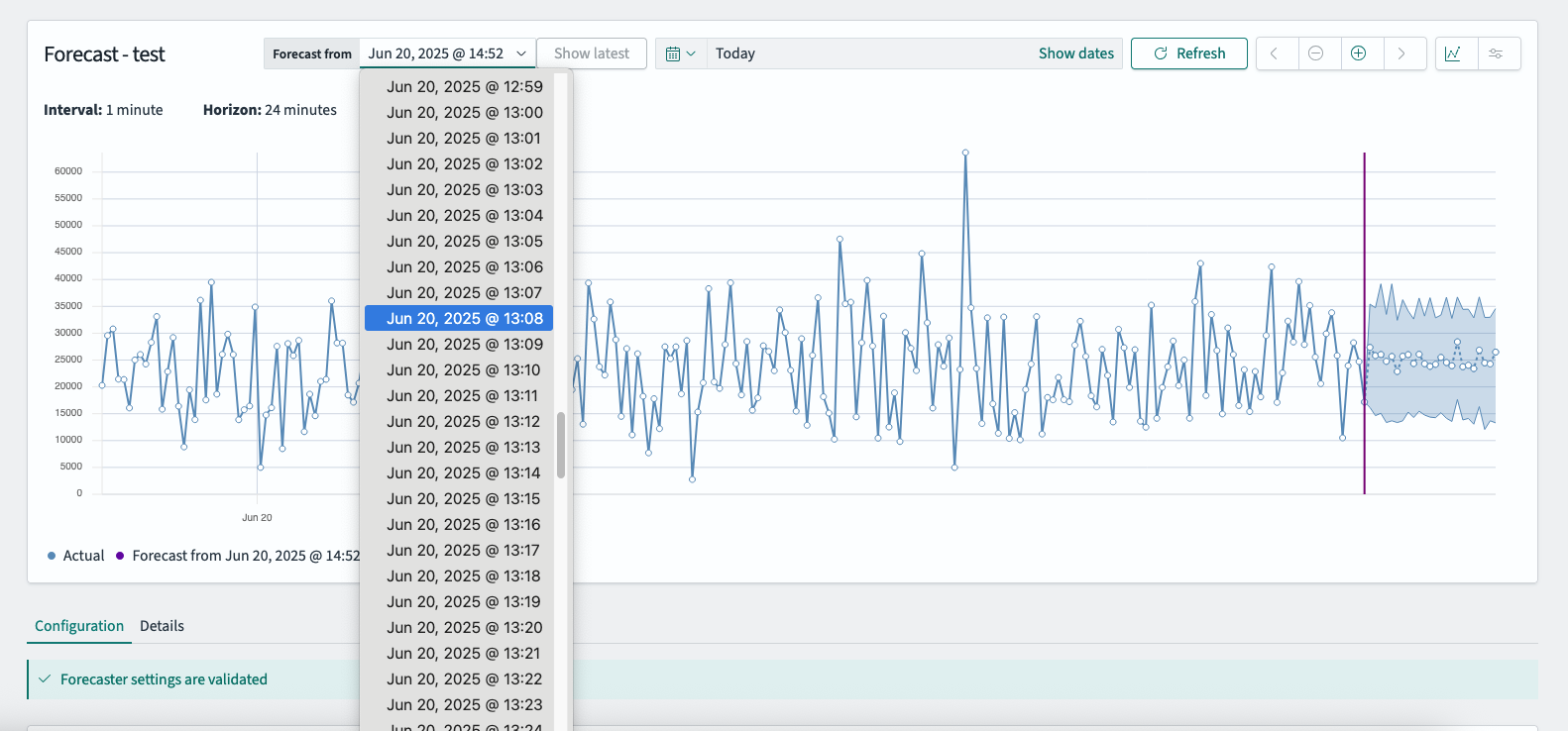
当您选择较早的**从以下日期预测**时间时,预测线将直接绘制在当时可用的历史数据之上。这会导致两个系列重叠,如下图所示。
要返回到最新的预测窗口,请选择**显示最新**。
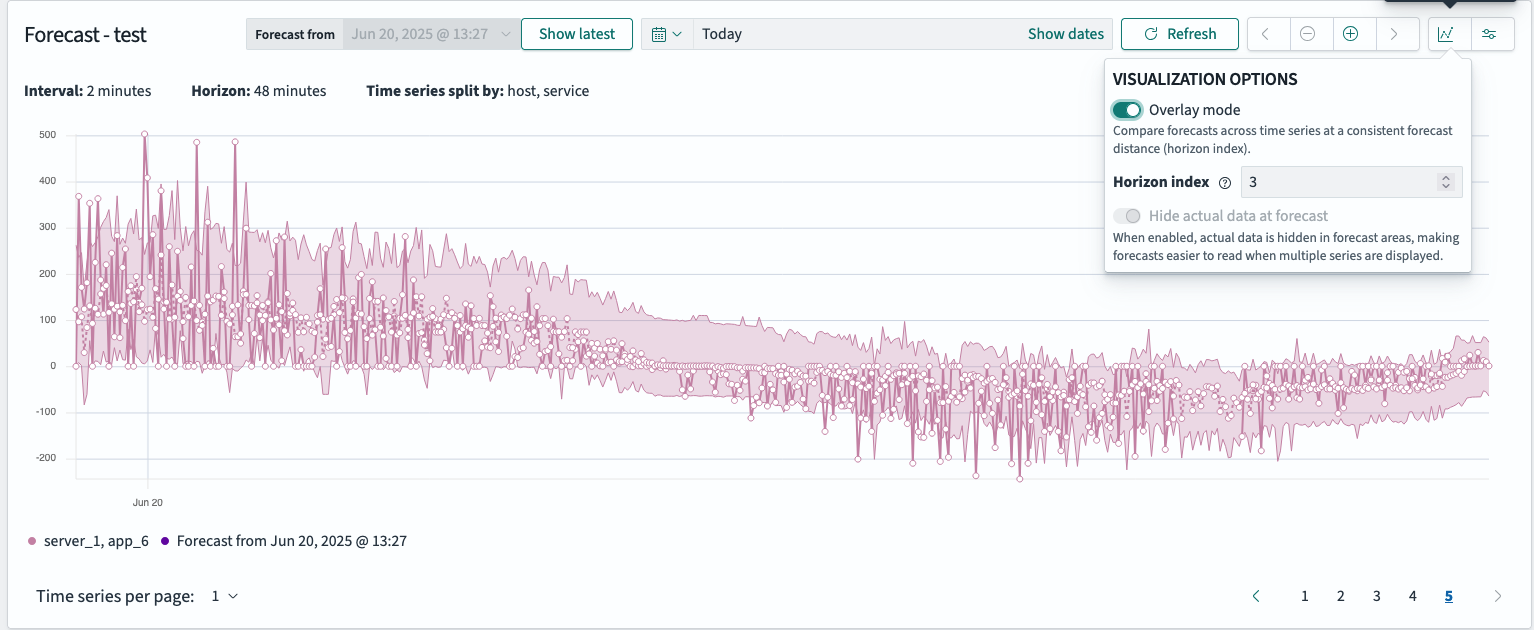
叠加模式:并排精度检查
默认情况下,图表显示从单个起始点开始的预测。切换到叠加模式可以将预测曲线直接叠加在实际序列之上,并检查整个时间轴的准确性。
由于模型为每个预测范围步长发出一个预测,例如当预测范围为 24 时会发出 24 个预测,因此单个时间戳可以有许多来自不同源的预测。叠加模式允许您决定绘制哪个提前期 (k):
- 预测范围索引 0 = 紧接的下一步
- 预测范围索引 1 = 提前 1 步
- 预测范围索引 23 = 提前 23 步
预测范围控件默认为**索引 3**,但您可以选择任何值以关注不同的提前期。
下图显示了启用叠加模式,预测步长指数为3。可视化将预测曲线(紫色)直接绘制在实际数据点(显示为白色填充标记)上方。这使您可以在整个时间线上评估模型提前三步预测的准确性。预测范围显示为预测值周围的阴影带,有助于突出不确定性。
查看多个预测序列
高基数预测器可以同时显示多个时间序列。使用结果面板中的每页时间序列下拉菜单,可以在以下视图之间切换
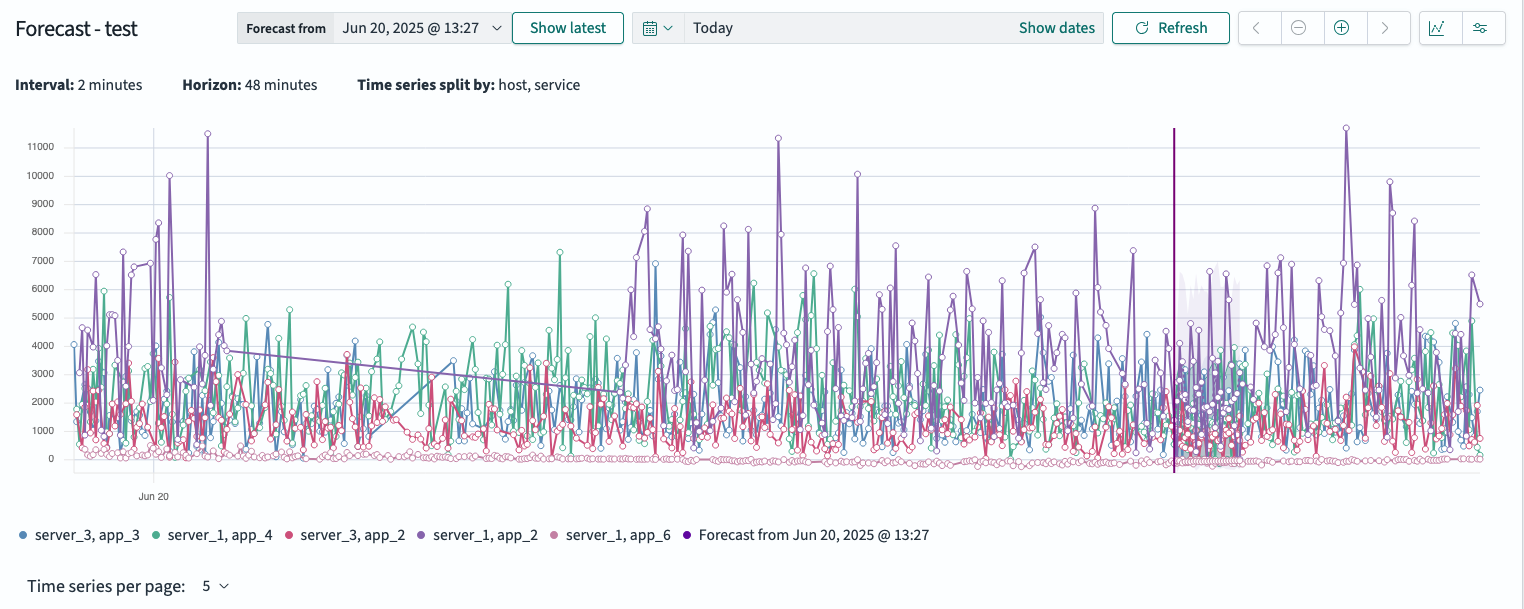
- 单序列视图(默认):每页渲染一个实体,以实现最大可读性。
- 多序列视图:并排绘制最多五个实体。置信带默认为半透明——将鼠标悬停在某条线上以突出显示其关联的置信带。
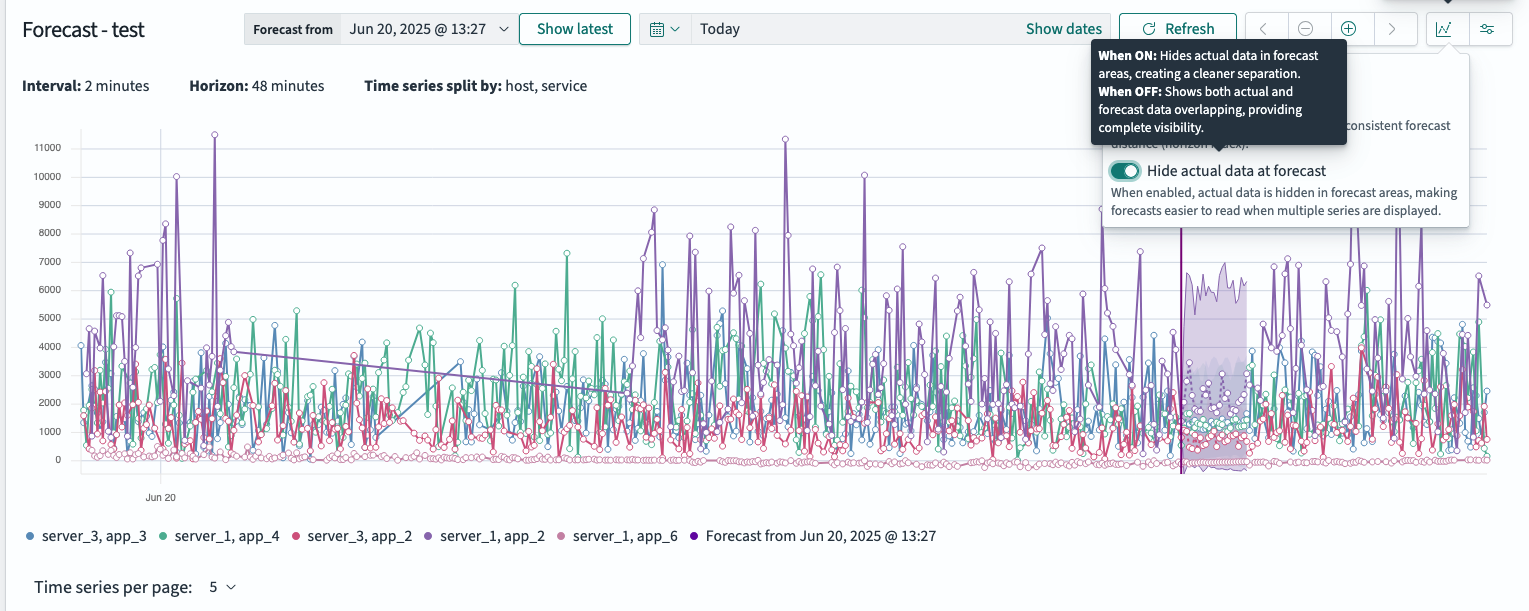
实际线和预测线重叠显示,以便您逐点评估准确性。但是,在多序列视图中,重叠的线条可能会使图表更难解释。为了减少视觉混乱,请转到可视化选项并关闭在预测时显示实际数据。
下图显示了实际线和预测线重叠的图表。
下图显示了相同的图表,但在预测时隐藏了实际线以简化视图。
探索时间线
使用以下时间线控件来导航、放大和筛选预测历史中的任何时间跨度
- 缩放 – 选择+ / – 以放大预测或拓宽上下文。
- 平移 – 使用箭头按钮移动到更早或更晚的数据点(如果有)。
- 快速 选择 – 选择常用范围,例如“最近24小时”,或为结果范围提供自定义日期。
多序列视图中的排序选项
当预测器跟踪的实体超过五个时,图表无法同时显示所有线条。
因此,在多序列视图中,您选择信息量最大的五个序列,并通过选择排序方法来决定“信息量大”的含义。下表列出了可用的排序方法。
| 排序方法 | 显示内容 | 何时使用 |
|---|---|---|
| 最小置信区间宽度 (默认) | 预测带最窄的五个序列。窄带表示模型对其预测高度确定。 | 呈现最“可信”的预测。 |
| 最大置信区间宽度 | 预测带最宽的五个序列——模型最不确定的预测。 | 发现可能需要审查或更多训练数据的有风险或噪声的序列。 |
| 预测范围内的最小值 | 每个实体在预测窗口内的最低预测点,按升序排序。 | 识别预计下降幅度最大的实体——对容量规划或潜在下降预警很有用。 |
| 预测范围内的最大值 | 每个实体在预测范围内的最高预测点,按降序排序。 | 突出显示预期高峰最大的序列,例如流量高峰或销量激增。 |
| 阈值距离 | 根据数值阈值(>、<、≥、≤)筛选预测,然后根据其余部分与该阈值的距离进行排序。 | 调查违反或接近违反SLA或业务KPI的实体,例如“显示任何预计超过10,000请求的预测”。 |
如果预测器监控的实体少于或等于五个,则多序列视图会显示所有实体。当实体数量超过五个时,每次更改排序方法或调整阈值时,视图都会动态重新排序,确保最相关的序列保持在焦点位置。
要关注实体的特定子集,请将筛选依据切换到自定义查询并输入查询DSL查询。以下示例显示了host等于server_1的实体。
{
"nested": {
"path": "entity",
"query": {
"bool": {
"must": [
{ "term": { "entity.name": "host" } },
{ "wildcard": { "entity.value": "server_1" } }
]
}
}
}
}
接下来,选择一种排序方法,例如预测范围内的最大值,然后选择更新可视化。图表将更新,仅显示host:server_1的预测序列,并根据您选择的条件进行排名。
编辑预测器
如果初始回测显示性能不佳,您可以调整预测器的配置并再次运行测试。
要编辑预测器
- 打开预测器的详细信息页面,然后选择编辑进入编辑模式。
- 根据需要修改设置——例如,添加类别字段、更改间隔或增加历史窗口。
-
选择更新。验证面板会自动评估新配置并标记任何问题。
下图显示了正在进行的验证过程。

- 解决所有验证错误。当面板变为绿色时,选择右上角的开始测试以使用更新后的参数再次运行回测。
实时预测
一旦您对预测配置有信心,请转到详细信息页面并单击开始预测以开始实时预测。预测器将根据每个前进间隔生成新的预测。
当图表与最新数据同步时,将显示一个实时徽章。
与回测不同,如果历史数据不足,实时预测会持续尝试使用实时数据进行初始化。在此初始化期间,预测器会显示初始化状态,直到它有足够的数据开始发出预测。
后续步骤
一旦您测试并优化了预测器,就可以开始使用它来生成实时预测或随时间管理它。要了解如何启动、停止、删除或更新现有预测器,请参阅管理预测器。