异常检测
OpenSearch 中的*异常*是指时间序列数据中任何不寻常的行为变化。异常可以为您的数据提供有价值的洞察。例如,对于 IT 基础设施数据,内存使用指标中的异常可以帮助识别系统故障的早期迹象。
可视化和仪表板等传统技术可能难以发现异常。虽然可以基于静态阈值配置警报,但这种方法需要先前的领域知识,并且可能不适用于具有自然增长或季节性趋势的数据。
异常检测使用随机切割森林(Random Cut Forest,RCF)算法,近乎实时地自动检测 OpenSearch 数据中的异常。RCF 是一种无监督机器学习算法,它根据传入数据流的草图建模,为每个传入数据点计算一个*异常等级*和*置信度分数*值。这些值用于区分异常与正常波动。有关 RCF 工作原理的更多信息,请参阅基于鲁棒随机切割森林的数据流异常检测。
您可以将异常检测插件与警报插件结合使用,以便在检测到异常时立即收到通知。
OpenSearch Dashboards 中的异常检测入门
要开始使用,请前往 OpenSearch Dashboards > OpenSearch 插件 > 异常检测。
步骤 1:定义检测器
检测器是一个独立的异常检测任务。您可以定义多个检测器,并且所有检测器可以同时运行,每个检测器分析来自不同来源的数据。您可以按照以下步骤定义检测器
- 在异常检测页面,选择创建检测器按钮。
-
在定义检测器页面,添加检测器详细信息。输入名称和简短描述。名称必须是唯一的,并且足够描述性,以帮助您识别检测器的目的。
-
在选择数据面板中,通过从索引下拉菜单中选择一个或多个源来指定数据源。您可以选择索引、索引模式或别名。
-
检测器可以使用远程索引,您可以通过
cluster-name:index-name模式访问这些索引。有关更多信息,请参阅跨集群搜索。从 OpenSearch Dashboards 2.17 开始,您也可以直接选择集群和索引。如果启用了安全插件,请参阅异常检测安全性文档中的使用细粒度访问控制选择远程索引。 -
要在 OpenSearch Dashboards 中创建跨集群检测器,您必须拥有以下权限:
indices:data/read/field_caps、indices:admin/resolve/index和cluster:monitor/remote/info。
-
- (可选)通过选择添加数据过滤器,然后指定字段、运算符和值的条件来过滤数据源。或者,选择使用查询 DSL 并以 JSON 格式输入您的过滤器作为布尔查询。查询领域特定语言 (DSL) 仅支持布尔查询。
示例:使用查询 DSL 过滤数据
以下示例查询检索 urlPath.keyword 字段与任何指定值匹配的文档
{
"bool": {
"should": [
{
"term": {
"urlPath.keyword": "/domain/{id}/short"
}
},
{
"term": {
"urlPath.keyword": "/sub_dir/{id}/short"
}
},
{
"term": {
"urlPath.keyword": "/abcd/123/{id}/xyz"
}
}
]
}
}
设置检测器间隔
在时间戳面板中,从时间戳字段下拉菜单中选择一个字段。
然后,在操作设置面板中,使用以下最佳实践来定义检测器间隔,即检测器收集数据的间隔
- 检测器将在此间隔内聚合数据,然后将聚合结果馈送到异常检测模型。间隔越短,检测器聚合的数据点越少。异常检测模型使用分片过程(shingling process),这是一种利用连续数据点为模型创建样本的技术。此过程需要来自连续间隔的特定数量的聚合数据点。
- 您应该根据实际数据设置检测器间隔。如果检测器间隔太长,可能会延迟结果。如果检测器间隔太短,可能会丢失一些数据。此外,检测器间隔将无法为分片过程提供足够的连续数据点。
- (可选)要为数据收集添加额外的处理时间,请指定一个窗口延迟值。
- 此值告知检测器数据并非实时摄入 OpenSearch,而是存在一定延迟。设置窗口延迟可偏移检测器间隔以考虑此延迟。
- 例如,检测器间隔为 10 分钟,并且数据摄入到您的集群中通常有 1 分钟的延迟。假设检测器在 2:00 运行。检测器尝试获取从 1:50 到 2:00 的最近 10 分钟数据,但由于 1 分钟的延迟,它只获取了 9 分钟的数据,并错过了从 1:59 到 2:00 的数据。将窗口延迟设置为 1 分钟会将间隔窗口偏移到 1:49–1:59,这样检测器就能考虑到检测器间隔时间内的所有 10 分钟数据。
- 为避免数据丢失,请将窗口延迟设置为预期摄入延迟的上限。这确保了检测器在其间隔内捕获所有数据,从而降低了丢失相关信息的风险。虽然较长的窗口延迟有助于捕获所有数据,但过长的窗口延迟可能会阻碍实时异常检测,因为检测器会回溯更长时间。请找到一个能同时保持数据准确性和及时检测的平衡点。
指定自定义结果索引
异常检测插件允许您将异常检测结果存储在您选择的自定义索引中。选择启用自定义结果索引并为您的索引提供一个名称,例如 abc。然后,插件会创建一个以 opensearch-ad-plugin-result- 为前缀的别名,后跟您选择的名称,例如 opensearch-ad-plugin-result-abc。此别名指向一个实际索引,该索引的名称包含日期和序列号,例如 opensearch-ad-plugin-result-abc-history-2024.06.12-000002,您的结果将存储在此处。
您可以使用 - 分隔命名空间来管理自定义结果索引权限。例如,如果您使用 opensearch-ad-plugin-result-financial-us-group1 作为结果索引,您可以基于模式 opensearch-ad-plugin-result-financial-us-* 创建一个权限角色,以细粒度级别代表 us 组中的 financial 部门。
权限
当安全插件(细粒度访问控制)启用时,默认结果索引会变成系统索引,并且不再能通过标准索引或搜索 API 访问。要访问其内容,您必须使用异常检测 RESTful API 或仪表板。因此,如果启用了安全插件,您无法使用默认结果索引构建自定义仪表板。但是,您可以创建一个自定义结果索引来构建自定义仪表板。
如果您指定的自定义索引不存在,异常检测插件将在您创建检测器并开始实时或历史分析时创建它。
如果自定义索引已存在,插件将验证索引映射是否与异常结果所需的结构匹配。在这种情况下,请确保自定义索引具有 anomaly-results.json 文件中定义的有效映射。要使用自定义结果索引选项,您必须拥有以下权限
indices:admin/create– 需要create权限才能创建和翻转自定义索引。indices:admin/aliases– 需要aliases权限才能为自定义索引创建和管理别名。indices:data/write/index– 需要write权限才能将结果写入单实体检测器的自定义索引。indices:data/read/search– 需要search权限才能搜索自定义结果索引,以便在异常检测界面上显示结果。indices:data/write/delete– 检测器可能会生成大量异常结果。需要delete权限才能删除旧数据并节省磁盘空间。indices:data/write/bulk*– 需要bulk*权限,因为插件使用批量 API 将结果写入自定义索引。
扁平化嵌套字段
包含嵌套字段的自定义结果索引映射会带来聚合和可视化方面的挑战。启用扁平化自定义结果索引选项会扁平化自定义结果索引中的嵌套字段。选择此选项后,插件会创建一个单独的索引,其前缀为自定义结果索引名称和检测器名称。例如,如果检测器 Test 使用自定义结果索引 abc,则一个带有别名 opensearch-ad-plugin-result-abc-flattened-test 的单独索引将存储已扁平化嵌套字段的异常检测结果。
除了创建单独的索引外,插件还会设置一个带有脚本处理器的摄入管道。此管道绑定到单独的索引,并使用 Painless 脚本扁平化自定义结果索引中的所有嵌套字段。
在运行中的检测器上停用此选项会移除其扁平化摄入管道;它也不再是结果索引的默认选项。使用扁平化自定义结果选项时,请考虑以下事项
- 异常检测插件根据自定义结果索引和检测器名称构建索引名称,由于检测器名称是可编辑的,因此可能会发生冲突。如果发生冲突,插件将重用索引名称。
- 管理自定义结果索引时,请考虑以下事项
- 异常检测仪表板会查询所有自定义结果索引中的所有检测器结果。自定义结果索引过多可能会影响插件的性能。
- 您可以使用索引状态管理来翻转旧的结果索引。您也可以手动删除或归档任何旧的结果索引。建议将一个自定义结果索引用于多个检测器。
当自定义结果索引满足下表中的任何条件时,插件会将别名翻转到一个新索引。
| 参数 | 描述 | 类型 | 单位 | 示例 | 必需 |
|---|---|---|---|---|---|
| 索引翻转所需的最小主分片总大小(不包括副本)。当设置为 100 GiB,并且索引有 5 个主分片和 5 个副本分片,每个 20 GiB 时,将执行翻转。 | 整型 | MB | 51200 | 否 |
| 翻转所需的最小索引年龄,从创建时间到当前时间计算。 | 整型 | 天 | 7 | 否 |
| 删除已翻转索引所需的最小年龄。 | 整型 | 天 | 60 | 否 |
下一步
定义检测器设置后,选择下一步。
定义检测器后,下一步是配置模型。
步骤 2:配置模型
为您的检测器添加特征。特征是字段或 Painless 脚本的聚合。检测器可以跨一个或多个特征发现异常。
您必须为每个特征选择一个聚合方法:average()、count()、sum()、min() 或 max()。聚合方法决定了什么构成异常。例如,如果您选择 min(),检测器将侧重于根据特征的最小值来查找异常。如果您选择 average(),检测器将根据特征的平均值来查找异常。
您也可以使用自定义 JSON 聚合查询作为聚合方法。有关创建 JSON 聚合查询的更多信息,请参阅查询 DSL。
对于每个已配置的特征,您还可以选择异常标准。默认情况下,当实际值异常高于或低于预期值时,模型会检测到异常。但是,您可以自定义特征设置,以便仅当实际值高于预期值(表示数据出现峰值)或低于预期值(表示数据出现低谷)时才注册异常。例如,在为 cpu_utilization 字段创建检测器时,您可能选择仅在值出现峰值时注册异常,以减少警报疲劳。
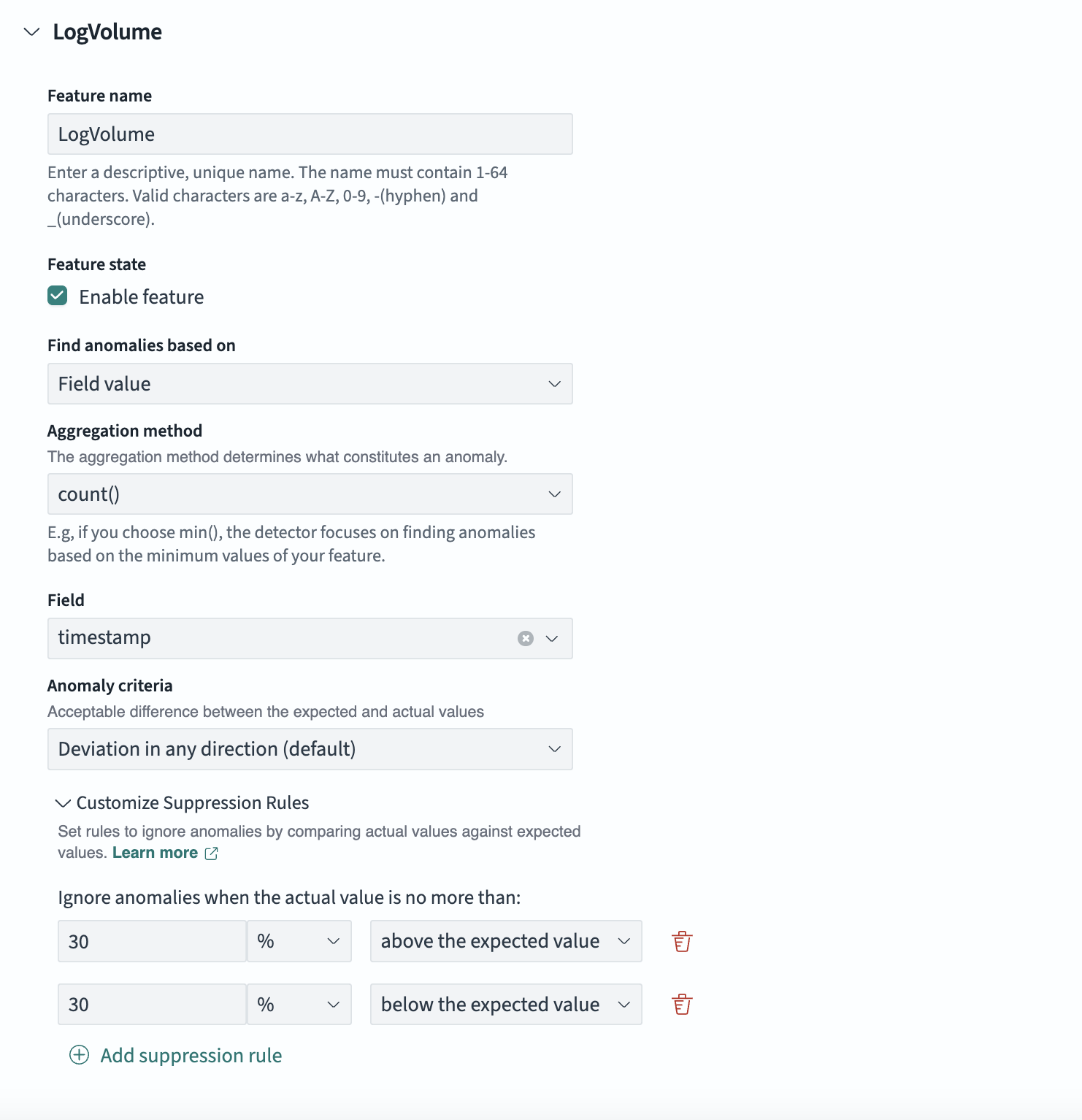
使用基于阈值的规则抑制异常
在特征选择面板中,您可以通过设置规则来抑制异常,这些规则定义了预期值和实际值之间的可接受差异,可以是绝对值或相对百分比。这有助于减少由微小波动引起的假异常,让您能够专注于显著偏差。
要抑制与预期值偏差小于 30% 的异常,您可以在特征选择面板中设置以下规则
- 当实际值不超过预期值 30% 时,忽略异常。
- 当实际值不低于预期值 30% 时,忽略异常。
下图显示了名为 LogVolume 的特征面板,您可以在其中设置相对偏差百分比设置
如果您希望日志量与预期值的差异至少达到 10,000 才被视为异常,您可以设置以下绝对阈值
- 当实际值不超过预期值 10,000 时,忽略异常。
- 当实际值不低于预期值 10,000 时,忽略异常。
下图显示了名为 LogVolume 的特征面板,您可以在其中设置绝对阈值设置

如果未设置自定义抑制规则,则系统默认为一个过滤器,该过滤器会忽略每个启用特征与预期值偏差小于 20% 的异常。
多特征模型会关联其所有特征中的异常。维度诅咒使得多特征模型识别较小异常的可能性低于单特征模型。添加更多特征可能会对模型的精确度和召回率产生负面影响。数据中更高比例的噪声会进一步放大这种负面影响。为了选择异常的最佳特征集限制,我们建议采用迭代过程来测试不同的限制。默认情况下,检测器的最大特征数为 5。要调整此限制,请使用 plugins.anomaly_detection.max_anomaly_features 设置。
基于聚合方法配置模型
要基于聚合方法配置异常检测模型,请按照以下步骤操作
- 在检测器页面上,从列表中选择所需的检测器。
- 在检测器的详细信息页面上,选择 操作 按钮以激活下拉菜单,然后选择 编辑模型配置。
- 在 编辑模型配置 页面上,选择 添加另一个特征 按钮。
- 在 特征名称 字段中输入名称,然后选中 启用特征 复选框。
- 在 根据以下条件查找异常 下拉菜单中选择 字段值。
- 在 聚合方法 下拉菜单中选择所需的聚合。
- 在 字段 下拉菜单中列出的选项中选择所需的字段。
- 选择 保存更改 按钮。
基于 JSON 聚合查询配置模型
要基于 JSON 聚合查询配置异常检测模型,请执行以下步骤
- 在 编辑模型配置 页面上,选择 添加另一个特征 按钮。
- 在 特征名称 字段中输入名称,然后选中 启用特征 复选框。
- 在 根据以下条件查找异常 下拉菜单中选择 自定义表达式。JSON 编辑器窗口将打开。
- 在编辑器中输入您的 JSON 聚合查询。
- 选择 保存更改 按钮。
有关可接受的 JSON 查询语法,请参阅 OpenSearch Query DSL。
设置高基数分类字段
您可以根据关键字或 IP 字段类型对异常进行分类。您可以启用 分类字段 选项,使用维度(例如 IP 地址、产品 ID 或国家代码)对源时间序列进行分类或“切片”。这为您提供了类别字段中每个实体的异常的粒度视图,有助于隔离和调试问题。
要设置类别字段,请选择 启用分类字段 并选择一个字段。创建检测器后,您无法更改类别字段。
类别字段中仅支持特定数量的唯一实体。使用以下公式计算集群中建议支持的实体总数
(data nodes * heap size * anomaly detection maximum memory percentage) / (entity model size of a detector)
要获取检测器的实体模型大小,请使用 配置文件检测器 API。您可以使用 plugins.anomaly_detection.model_max_size_percent 设置调整最大内存百分比。
考虑一个具有 3 个数据节点,每个节点具有 8 GB JVM 堆大小和默认 10% 内存分配的集群。实体模型大小为 1 MB 时,以下公式计算唯一实体的估计数量
(8096 MB * 0.1 / 1 MB ) * 3 = 2429
如果实际的唯一实体总数高于您计算的数量(在此示例中为 2,429),则异常检测器会尝试对额外实体进行建模。检测器会优先考虑出现频率更高和最近出现的实体。
此公式仅作参考。请务必使用代表性工作负载对其进行测试。有关更多信息,请参阅 OpenSearch 博客文章 改进异常检测:一分钟内处理一百万个实体。
设置 shingle 大小
在 高级设置 面板中,您可以设置检测窗口中包含的数据流聚合间隔数量。根据您的实际数据选择此值,以找到适合您用例的最佳设置。要设置 shingle 大小,请在 高级设置 面板中选择 显示。在 间隔 字段中输入所需的大小。
异常检测器要求 shingle 大小介于 1 到 128 之间。默认值为 8。仅当您至少有两个特征时才使用 1。小于 8 的值可能会提高 召回率,但也可能增加误报。大于 8 的值可能有助于忽略信号中的噪声。
设置插补选项
在 高级设置 面板中,您可以设置插补选项。这允许您管理流中的缺失数据。选项包括以下内容
- 忽略缺失数据(默认):系统继续运行,不考虑缺失数据点,保持现有数据流。
- 使用自定义值填充:为每个特征指定一个自定义值来替换缺失数据点,从而实现针对您数据量身定制的定向插补。
- 用零填充:用零替换缺失值。当数据的缺失表示一个重要事件时,例如事件计数降至零时,这是理想选择。
- 使用先前值:用最后观测到的值填充空白,以保持时间序列数据的连续性。此方法将缺失数据视为非异常,并延续之前的趋势。
使用这些选项可以提高异常检测的召回率。例如,如果您正在监控事件计数下降(包括部分和完全下降),那么用零填充缺失值有助于检测显着的数据缺失,从而提高检测召回率。
在插补大量缺失数据时要谨慎,因为过多的空白可能会损害模型准确性。高质量的输入至关重要——数据质量差会导致模型性能差。发生插补时,置信度分数也会降低。您可以使用异常结果索引中的 feature_imputed 字段检查特征值是否已插补。有关更多信息,请参阅 异常结果映射。
预览示例异常
您可以根据示例特征输入预览异常,并根据需要调整特征设置。异常检测插件选择少量数据样本(例如,每 30 分钟一个数据点),并使用插值来估计其余数据点,以近似实际特征数据。样本数据集加载到检测器中,检测器随后使用样本数据集生成异常预览。
- 选择 预览示例异常。
- 如果未显示示例异常结果,请检查检测器间隔,以验证在预览日期范围内是否为实体设置了 400 个或更多数据点。
- 选择 下一步 按钮。
步骤 3:设置检测器作业
要启动检测器以近乎实时地在数据中查找异常,请选择 自动启动实时检测器(推荐)。
或者,如果您想执行历史分析并在更长的历史数据窗口(数周或数月)中查找模式,请选中 运行历史分析检测 复选框,并选择至少 128 个检测间隔的日期范围。
分析历史数据可以帮助您熟悉异常检测插件。例如,您可以根据历史数据评估检测器的性能,以便对其进行微调。
您可以使用不同的特征集进行历史分析实验,并在使用实时检测器之前检查精度。
步骤 4:审查检测器设置
审查您的检测器设置和模型配置以确认其有效性,然后选择 创建检测器。
如果发生验证错误,请编辑设置以更正错误并返回检测器页面。
步骤 5:观察结果
选择 实时结果 或 历史分析 选项卡。对于实时结果,显示异常结果需要一些时间。例如,如果检测器间隔为 10 分钟,则检测器可能需要一小时才能启动,因为它正在等待足够的数据才能生成异常。
更短的间隔使模型更快地通过 shingle 过程并更早地生成异常结果。您可以使用 配置文件检测器 操作来确保您有足够的数据点。
如果检测器在“初始化”中待定超过 1 天,请聚合您的现有数据并使用检测器间隔检查是否有任何缺失数据点。如果您发现许多缺失数据点,请考虑增加检测器间隔。
单击并拖动异常折线图以放大并查看异常的详细视图。
您可以使用以下可视化分析异常
- 实时异常(适用于实时结果)显示过去 60 个间隔的实时异常结果。例如,如果间隔为
10,则显示过去 600 分钟的结果。图表每 30 秒刷新一次。 - 异常概述(适用于实时结果)或 异常历史(适用于 历史分析 选项卡上的历史分析)绘制异常等级和相应的置信度度量。该面板包括
- 根据给定数据时间范围的异常发生次数。
- 平均异常等级,一个介于 0 和 1 之间的数字,指示数据点的异常程度。异常等级为
0表示“不是异常”,非零值表示异常的相对严重性。 - 置信度,估算报告的异常等级与预期异常等级匹配的概率。随着模型观察更多数据并学习数据行为和趋势,置信度会增加。请注意,置信度与模型准确性不同。
- 最后一次异常发生时间 是最后一次异常发生的时间。
以下部分可以在 异常概述 和 异常历史 下找到
-
特征分解 根据聚合方法绘制特征。您可以更改检测器的时间范围。选择特征折线图上的一个点会显示 特征输出(字段在索引中出现的次数)和 预期值(特征输出的预测值)。如果没有异常,则输出值和预期值相等。
-
异常发生 显示每个检测到的异常的
Start time(开始时间)、End time(结束时间)、Data confidence(数据置信度)和Anomaly grade(异常等级)。要在 Discover 中查看与发生事件相关的日志,请在 操作 列中选择 在 Discover 中查看 图标。日志包含开始时间和结束时间前后 10 分钟的缓冲区。
选择异常折线图上的一个点会显示 特征贡献,即特征对异常的贡献百分比
如果您设置了类别字段,则会看到一个额外的 热力图。热力图关联异常实体的结果。此图表在您选择异常实体之前为空。您还会看到异常发生时段(anomaly_grade > 0)的异常和特征折线图。
如果您设置了多个类别字段,则可以选择字段子集以进行筛选和排序。选择字段子集可以让您查看与另一个字段共享公共值的字段的顶部值。
例如,如果您的检测器具有类别字段 ip 和 endpoint,您可以在 查看方式 下拉菜单中选择 endpoint。然后选择一个特定的单元格,将 ip 的前 20 个值叠加到图表上。异常检测插件默认选择前 ip。您最多可以同时查看 5 个单独的时间序列值。
步骤 6:设置警报
在 实时结果 下,选择 设置警报 并配置监视器,以便在检测到异常时通知您。有关根据您的异常检测器创建监视器和设置通知的步骤,请参阅 监视器。
如果您停止或删除检测器,请务必删除与其关联的任何监视器。
步骤 7:调整模型
要查看检测器的所有配置设置,请选择 检测器配置 选项卡。
- 要更改检测器配置或微调时间间隔以最大程度地减少误报,请转到 检测器配置 部分并选择 编辑。
- 您需要停止实时和历史分析以更改其配置。确认您要停止检测器并继续。
- 要启用或禁用特征,请在 特征 部分中,选择 编辑 并根据需要调整特征设置。进行更改后,选择 保存并启动检测器。
步骤 8:管理您的检测器
要启动、停止或删除检测器,请转到 检测器 页面。
- 选择检测器名称。
- 选择 操作 并选择 启动实时检测器、停止实时检测器 或 删除检测器。