策略
策略是定义以下内容的 JSON 文档:
- 索引可以处于的状态,包括新索引的默认状态。例如,您可以将状态命名为“hot”、“warm”、“delete”等。欲了解更多信息,请参阅状态。
- 当索引进入某个状态时,您希望插件采取的任何操作,例如执行滚动更新。欲了解更多信息,请参阅操作。
- 索引进入新状态必须满足的条件,称为转换。例如,如果索引已超过八周,您可能希望将其移动到“delete”状态。欲了解更多信息,请参阅转换。
换句话说,策略定义了索引可以处于的状态、在某个状态下要执行的操作以及在状态之间进行转换必须满足的条件。
您可以完全灵活地设计策略。您可以创建任何状态,转换为任何其他状态,并在每个状态中指定任意数量的操作。
此表列出了策略的相关字段。
| 字段 | 描述 | 类型 | 必需 | 只读 |
|---|---|---|---|---|
policy_id | 策略的名称。 | 字符串 | 是 | 是 |
description | 策略的人类可读描述。 | 字符串 | 是 | 否 |
ism_template | 指定 ISM 模板以自动将策略应用于新创建的索引。 | 嵌套对象列表 | 否 | 否 |
ism_template.index_patterns | 指定一个与新创建的索引名称匹配的模式。 | 字符串列表 | 否 | 否 |
ism_template.priority | 当多个策略匹配新创建的索引名称时,指定优先级以消除歧义。 | 数字 | 否 | 否 |
last_updated_time | 策略上次更新的时间。 | 时间戳 | 是 | 是 |
error_notification | 错误通知的目标和消息模板。目标可以是 Amazon Chime、Slack 或 webhook URL。 | 对象 | 否 | 否 |
default_state | 使用此策略的每个索引的默认起始状态。 | 字符串 | 是 | 否 |
states | 您在策略中定义的状态。 | 嵌套对象列表 | 是 | 否 |
目录
状态
状态是对受管索引当前所处状态的描述。受管索引一次只能处于一个状态。每个状态都具有关联的操作,这些操作在进入状态时按顺序执行,并在所有操作完成后检查转换。
此表列出了您可以为状态定义的参数。
| 字段 | 描述 | 类型 | 必需 |
|---|---|---|---|
名称 | 状态的名称。 | 字符串 | 是 |
actions | 进入状态后要执行的操作。欲了解更多信息,请参阅操作。 | 嵌套对象列表 | 是 |
transitions | 下一个状态以及转换为这些状态所需的条件。如果没有转换,策略会假定已完成,并且可以停止管理索引。欲了解更多信息,请参阅转换。 | 嵌套对象列表 | 是 |
动作
操作是策略在进入特定状态时按顺序执行的步骤。
ISM 按定义的顺序执行操作。例如,如果您定义操作 [A,B,C,D],ISM 会执行操作 A,然后根据集群设置 plugins.index_state_management.job_interval 进入休眠期。休眠期结束后,ISM 会继续执行剩余操作。但是,如果 ISM 无法成功执行操作 A,则操作将终止,并且操作 B、C 和 D 将不会执行。
您可以选择定义操作的超时期限,如果超出此期限,操作将强制失败。例如,如果超时设置为 1d,并且 ISM 在一天内未能完成操作,即使经过重试,操作也会失败。
此表列出了您可以为操作定义的参数。
| 参数 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
timeout | 操作的超时期限。接受分钟、小时和天的时间单位。 | 时间单位 | 否 | - |
retry | 操作的重试配置。 | 对象 | 否 | 特定于操作 |
retry 操作具有以下参数:
| 参数 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
count | 重试次数。 | 数字 | 是 | - |
backoff | 重试时使用的退避策略类型。有效值为 Exponential、Constant 和 Linear。 | 字符串 | 否 | Exponential |
delay | 重试之间等待的时间。接受分钟、小时和天的时间单位。 | 时间单位 | 否 | 1 分钟 |
以下示例操作的超时期限为一小时。策略将使用指数退避策略重试此操作三次,每次重试之间延迟 10 分钟。
"actions": {
"timeout": "1h",
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "10m"
}
}
有关可用单位类型的列表,请参阅支持的单位。
ISM 支持的操作
ISM 支持以下操作:
- force_merge
- read_only
- read_write
- replica_count
- shrink
- close
- 打开
- 删除
- rollover
- notification
- 快照
- convert-index-to-remote
- index_priority
- allocation
- rollup
- stop_replication
force_merge
通过合并单个分段的段来减少 Lucene 段的数量。此操作尝试在开始合并过程之前将索引设置为只读状态。
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
max_num_segments | 将分片减少到的段数。 | 数字 | 是 |
wait_for_completion | 布尔型 | 当设置为 false 时,请求会立即返回,而不是在操作完成后返回。要监控操作状态,请使用请求返回的任务 ID 调用任务 API。默认值为 true。 | |
task_execution_timeout | 时间 | 显式任务执行超时。仅当 wait_for_completion 设置为 false 时才有用。默认值为 1h。 | 否 |
{
"force_merge": {
"max_num_segments": 1
}
}
read_only
将受管索引设置为只读。
{
"read_only": {}
}
将受管索引的索引设置 index.blocks.write 设置为 true。*注意:此阻塞不会阻止索引刷新。
read_write
将受管索引设置为可写入。
{
"read_write": {}
}
replica_count
设置要分配给索引的副本数量。
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
number_of_replicas | 定义要分配给索引的副本数量。 | 数字 | 是 |
{
"replica_count": {
"number_of_replicas": 2
}
}
有关设置副本的信息,请参阅主分片和副本分片。
shrink
允许您减少索引中的主分片数量。通过此操作,您可以指定:
- 目标索引应包含的主分片数量。
- 目标索引中主分片的最大分片大小。
- 指定一个百分比来收缩目标索引中主分片的数量。
"shrink": {
"num_new_shards": 1,
"target_index_name_template": {
"source": "_shrunken"
},
"aliases": [
{
"my-alias": {}
}
],
"switch_aliases": true,
"force_unsafe": false
}
| 参数 | 描述 | 类型 | 示例 | 必需 |
|---|---|---|---|---|
num_new_shards | 收缩索引中主分片的最大数量。 | 整数 | 5 | 是。但是,它不能与 max_shard_size 或 percentage_of_source_shards 一起使用。 |
max_shard_size | 目标索引中分片的最大大小(以字节为单位)。 | 关键字 | 5gb | 是,但是,它不能与 num_new_shards 或 percentage_of_source_shards 一起使用。 |
percentage_of_source_shards | 收缩原始主分片数量的百分比。此参数表示在收缩主分片数量时要使用的最小百分比。必须介于 0.0 和 1.0 之间,不包括 0.0 和 1.0。 | 百分比 | 0.5 | 是,但是它不能与 max_shard_size 或 num_new_shards 一起使用 |
target_index_name_template | 收缩索引的名称。接受字符串和 Mustache 变量 and。 | 字符串或 Mustache 模板 | {"source": "_shrunken"} | 否 |
aliases | 要添加到新索引的别名。 | 对象 | myalias | 否。它必须是别名对象的数组。 |
switch_aliases | 如果为 true,则将源索引中的别名复制到目标索引。如果与 aliases 字段中的别名存在名称冲突,则使用 aliases 字段中的别名而不是名称。 | 布尔型 | true | 否。默认隐式值为 false,这意味着默认情况下不会复制别名。 |
force_unsafe | 如果为 true,即使索引没有副本也会收缩。 | 布尔型 | false | 否 |
如果要将 aliases 添加到操作中,参数必须包含别名对象的数组。例如,
"aliases": [
{
"my-alias": {}
},
{
"my-second-alias": {
"is_write_index": false,
"filter": {
"multi_match": {
"query": "QUEEN",
"fields": ["speaker", "text_entry"]
}
},
"index_routing" : "1",
"search_routing" : "1"
}
},
]
close
关闭受管索引。
{
"close": {}
}
已关闭的索引保留在磁盘上,但不消耗 CPU 或内存。您无法读取、写入或搜索已关闭的索引。
如果您需要保留数据的时间比主动搜索数据的时间更长,并且数据节点上有足够的磁盘空间,则关闭索引是一个不错的选择。如果需要再次搜索数据,重新打开已关闭的索引比从快照恢复索引更简单。
打开
打开受管索引。
{
"open": {}
}
删除
删除受管索引。
{
"delete": {}
}
rollover
当受管索引满足其中一个滚动更新条件时,将别名滚动更新到新索引。
ISM 根据设定的间隔检查操作条件,且检查发生在策略的每次执行时,而不是连续进行。如果值在执行检查时已经达到或超过配置的限制,则将执行滚动更新。例如,如果 min_size 配置为 100GiB,ISM 可能会在索引大小为 99 GiB 时检查但不执行滚动更新。然而,如果在下一次检查时索引大小已超过限制(例如 105GiB),则会执行该操作。
如果您需要跳过滚动更新操作,可以将索引设置 index.plugins.index_state_management.rollover_skip 设置为 true。例如,如果您收到错误消息“Missing alias or not the write index…”,您可以将 index.plugins.index_state_management.rollover_skip 参数设置为 true 并重试以跳过滚动更新操作。
索引格式必须匹配模式:^.*-\d+$。例如,(logs-000001)。将 index.plugins.index_state_management.rollover_alias 设置为要滚动更新的别名。
| 参数 | 描述 | 类型 | 示例 | 必需 |
|---|---|---|---|---|
min_size | 滚动更新索引所需的总主分片存储的最小大小(不包括副本)。例如,如果您将 min_size 设置为 100 GiB,并且您的索引有 5 个主分片和 5 个副本分片,每个 20 GiB,则所有主分片的总大小为 100 GiB,因此会发生滚动更新。请参阅上方的重要说明。 | 字符串 | 20gb 或 5mb | 否 |
min_primary_shard_size | 滚动更新索引所需的单个主分片的最小存储大小。例如,如果您将 min_primary_shard_size 设置为 30 GiB,并且索引中其中一个主分片的大小大于条件,则会发生滚动更新。请参阅上方的重要说明。 | 字符串 | 20gb 或 5mb | 否 |
min_doc_count | 滚动更新索引所需的最小文档数量。请参阅上方的重要说明。 | 数字 | 2000000 | 否 |
min_index_age | 滚动更新索引所需的最小年龄。索引年龄是其创建时间与当前时间之间的时间。支持的单位有 d(天)、h(小时)、m(分钟)、s(秒)、ms(毫秒)和 micros(微秒)。请参阅上方的重要说明。 | 字符串 | 5d 或 7h | 否 |
copy_alias | 控制是否将所有别名从当前索引复制到新创建的索引。默认为 false。 | 布尔值 | true 或 false | 否 |
{
"rollover": {
"min_size": "50gb"
}
}
{
"rollover": {
"min_primary_shard_size": "30gb"
}
}
{
"rollover": {
"min_doc_count": 100000000
}
}
{
"rollover": {
"min_index_age": "30d"
}
}
notification
向您发送通知。
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
destination | 目标 URL。 | Slack、Amazon Chime 或 webhook URL | 是 |
message_template | 消息文本。您可以使用 Mustache 模板向消息中添加变量。 | 对象 | 是 |
目标系统必须返回响应,否则通知操作将抛出错误。
示例 1:Chime 通知
{
"notification": {
"destination": {
"chime": {
"url": "<url>"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
示例 2:自定义 webhook 通知
{
"notification": {
"destination": {
"custom_webhook": {
"url": "https://<your_webhook>"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
示例 3:Slack 通知
{
"notification": {
"destination": {
"slack": {
"url": "https://hooks.slack.com/services/xxx/xxxxxx"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
您可以在消息中使用 ctx 变量来表示基于策略过去执行的多个策略参数。例如,如果您的策略包含滚动更新操作,您可以在消息中使用 {{ctx.action.name}} 来表示滚动更新的名称。
每个策略都提供以下 ctx 变量选项:
保证变量
| 参数 | 描述 | 类型 |
|---|---|---|
index | 索引的名称。 | 字符串 |
index_uuid | 索引的 uuid。 | 字符串 |
policy_id | 策略的名称。 | 字符串 |
快照
备份集群的索引和状态。有关快照的更多信息,请参阅拍摄和恢复快照。
snapshot 操作具有以下参数:
| 参数 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
repository | 您通过原生快照 API 操作注册的存储库名称。 | 字符串 | 是 | - |
快照 | 快照的名称。接受字符串和 Mustache 变量 and。如果 Mustache 变量无效,则快照名称默认为索引的名称。 | string 或 Mustache 模板 | 是 | - |
{
"snapshot": {
"repository": "my_backup",
"snapshot": ""
}
}
convert_index_to_remote
将索引从本地快照存储库转换为远程存储库。
convert_index_to_remote 操作具有以下参数。
| 参数 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
repository | 通过原生快照 API 操作注册的存储库名称。 | 字符串 | 是 | 不适用 |
快照 | 通过快照操作创建的快照名称。 | 字符串 | 是 | 不适用 |
确保 convert_index_to_remote 操作中使用的存储库名称与快照操作期间指定的存储库名称匹配。此外,您可以使用 来引用快照,如下面的示例策略所示:
{
"snapshot": {
"repository": "my_backup",
"snapshot": ""
},
"convert_index_to_remote": {
"repository": "my_backup",
"snapshot": ""
}
}
index_priority
设置索引在特定状态下的优先级。索引的未分配分片(如果可能)会按其优先级顺序恢复。优先级值较高的索引会首先恢复,然后是优先级值较低的索引。
index_priority 操作具有以下参数:
| 参数 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
priority | 索引一旦进入某个状态的优先级。 | 数字 | 是 | 1 |
"actions": [
{
"index_priority": {
"priority": 50
}
}
]
allocation
将索引分配给具有特定属性集的节点,就像这样。例如,将 require 设置为 warm 会将您的数据仅移动到“warm”节点。
allocation 操作有以下参数
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
require | 将索引分配给具有指定属性的节点。 | 字符串 | 是 |
include | 将索引分配给具有任意指定属性的节点。 | 字符串 | 是 |
exclude | 不要将索引分配给具有任何指定属性的节点。 | 字符串 | 是 |
wait_for | 等待策略执行完毕,然后再将索引分配给具有指定属性的节点。 | 字符串 | 是 |
"actions": [
{
"allocation": {
"require": { "temp": "warm" }
}
}
]
rollup
索引汇总 允许您通过将旧数据汇总到摘要索引中来定期降低数据粒度。
汇总作业可以是连续的或非连续的。使用 ISM 策略创建的汇总作业只能是非连续的。
stop_replication
停止复制并将跟随索引转换为常规索引。
{
"stop_replication": {}
}
启用跨集群复制后,跟随索引将变为只读,阻止所有写入操作。要在跟随集群上管理复制索引,您可以在执行其他写入操作之前执行 stop_replication 操作。例如,您可以定义一个策略,该策略首先运行 stop_replication,然后通过运行 delete 操作删除索引。
如果启用了安全性,除了 停止复制权限,您还必须拥有 indices:internal/plugins/replication/index/stop 权限才能使用 stop_replication 操作。
端点
PUT _plugins/_rollup/jobs/<rollup_id>
GET _plugins/_rollup/jobs/<rollup_id>
DELETE _plugins/_rollup/jobs/<rollup_id>
POST _plugins/_rollup/jobs/<rollup_id>/_start
POST _plugins/_rollup/jobs/<rollup_id>/_stop
GET _plugins/_rollup/jobs/<rollup_id>/_explain
ISM 汇总策略示例
{
"policy": {
"description": "Sample rollup" ,
"default_state": "rollup",
"states": [
{
"name": "rollup",
"actions": [
{
"rollup": {
"ism_rollup": {
"description": "Creating rollup through ISM",
"target_index": "target",
"target_index_settings":{
"index.number_of_shards": 1,
"index.number_of_replicas": 1,
"index.codec": "best_compression"
},
"page_size": 1000,
"dimensions": [
{
"date_histogram": {
"fixed_interval": "60m",
"source_field": "order_date",
"target_field": "order_date",
"timezone": "America/Los_Angeles"
}
},
{
"terms": {
"source_field": "customer_gender",
"target_field": "customer_gender"
}
},
{
"terms": {
"source_field": "day_of_week",
"target_field": "day_of_week"
}
}
],
"metrics": [
{
"source_field": "taxless_total_price",
"metrics": [
{
"sum": {}
}
]
},
{
"source_field": "total_quantity",
"metrics": [
{
"avg": {}
},
{
"max": {}
}
]
}
]
}
}
}
],
"transitions": []
}
]
}
}
请求正文字段
创建 ISM 策略时需要请求字段。您可以参考 索引汇总 API 页面获取请求字段选项。
在 Dashboards 中添加汇总策略
要在 Dashboards 中添加汇总策略,请按照以下步骤操作。
- 选择 Dashboards 用户界面左上角的菜单按钮。
- 在 Dashboards 菜单中,选择
Index Management。 - 在下一个屏幕上选择
Rollup jobs。 - 选择
Create rollup按钮。 - 按照
Create rollup job向导中的步骤操作。 - 在
Name框中为策略添加一个名称。 - 您可以参考 索引汇总 API 页面来配置汇总策略。
- 最后,选择 Dashboards 用户界面右下角的
Create按钮。
转换
转换定义了状态改变所需的条件。当前状态中的所有操作完成后,策略将开始检查转换条件。
ISM 按照定义的顺序评估转换。例如,如果您定义了转换:[A,B,C,D],ISM 会遍历此转换列表,直到找到一个评估为 true 的转换,然后停止并将下一个状态设置为该转换中定义的状态。在其下一次执行时,ISM 会忽略其余的转换,并从该新状态开始。
如果您在转换中未指定任何条件并将其留空,则假定其等同于始终为真。这意味着策略在检查时立即将索引转换为此状态。
此表列出了您可以为转换定义的参数。
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
state_name | 如果满足条件,要转换到的状态的名称。 | 字符串 | 是 |
conditions | 列出转换的条件。 | list | 是 |
conditions 对象有以下参数
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
min_index_age | 索引转换所需的最小年龄。 | 字符串 | 否 |
min_rollover_age | 发生翻转后,转换到下一状态所需的最小年龄。 | 字符串 | 否 |
min_doc_count | 索引转换所需的最小文档数量。 | 数字 | 否 |
min_size | 转换所需的总主分片存储的最小大小(不包括副本)。例如,如果您将 min_size 设置为 100 GiB,并且您的索引有 5 个主分片和 5 个副本分片,每个 20 GiB,则所有主分片的总大小为 100 GiB,因此您的索引将转换到下一状态。 | 字符串 | 否 |
cron | 如果其他转换未首先发生,则触发转换的 cron 作业。 | 对象 | 否 |
cron.cron.expression | 触发转换的 cron 表达式。 | 字符串 | 是 |
cron.cron.timezone | 触发转换的时区。 | 字符串 | 是 |
以下示例在 30 天后将索引转换为 cold 状态
"transitions": [
{
"state_name": "cold",
"conditions": {
"min_index_age": "30d"
}
}
]
ISM 根据设定的间隔在策略的每次执行时检查条件。
此示例使用 cron 条件在每周六太平洋时间 5:00 转换索引
"transitions": [
{
"state_name": "cold",
"conditions": {
"cron": {
"cron": {
"expression": "* 17 * * SAT",
"timezone": "America/Los_Angeles"
}
}
}
}
]
请注意,此条件并非在下午 5:00 整执行;作业仍根据 job_interval 设置执行。由于启动时间的这种差异以及在检查转换条件之前完成操作所需的时间,我们不建议使用过于狭窄的 cron 表达式。例如,不要使用 15 17 * * SAT(周六下午 5:15)。
一个小时的窗口(此示例中使用)通常足够了,但您可以将其增加到 2-3 小时,以避免错过窗口并等待一周才能发生转换。或者,您可以使用更广泛的表达式,例如 * * * * SAT,SUN,以便在周末的任何时间进行转换。
有关编写 cron 表达式的信息,请参阅 Cron 表达式参考。
错误通知
error_notification 操作会在您的托管索引失败时向您发送通知。它会向单个目标或 通知通道 发送自定义消息。
在策略级别设置错误通知
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"error_notification": { },
"states": [ ]
}
}
| 参数 | 描述 | 类型 | 必需 |
|---|---|---|---|
destination | 目标 URL。 | Slack、Amazon Chime 或 webhook URL | 如果未指定 channel 则为“是” |
channel | 通知通道的 ID | 字符串 | 如果未指定 destination 则为“是” |
message_template | 消息文本。您可以使用 Mustache 模板向消息中添加变量。 | 对象 | 是 |
目标系统**必须**返回响应,否则 error_notification 操作将抛出错误。
示例 1:Chime 通知
{
"error_notification": {
"destination": {
"chime": {
"url": "<url>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
示例 2:自定义 webhook 通知
{
"error_notification": {
"destination": {
"custom_webhook": {
"url": "https://<your_webhook>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
示例 3:Slack 通知
{
"error_notification": {
"destination": {
"slack": {
"url": "https://hooks.slack.com/services/xxx/xxxxxx"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
示例 4:使用通知通道
{
"error_notification": {
"channel": {
"id": "some-channel-config-id"
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
您可以为 ctx 变量使用与 通知 操作相同的选项。
带有 ISM 模板的自动滚动更新示例策略
以下示例模板策略适用于翻转用例。
如果您想跳过索引的翻转,请在该索引的设置中将 index.plugins.index_state_management.rollover_skip 设置为 true。
-
创建带有
ism_template字段的策略PUT _plugins/_ism/policies/rollover_policy { "policy": { "description": "Example rollover policy.", "default_state": "rollover", "states": [ { "name": "rollover", "actions": [ { "rollover": { "min_doc_count": 1 } } ], "transitions": [] } ], "ism_template": { "index_patterns": ["log*"], "priority": 100 } } }您需要指定
index_patterns字段。如果您未指定priority的值,则默认为 0。 -
设置一个以
log作为rollover_alias的模板PUT _index_template/ism_rollover { "index_patterns": ["log*"], "template": { "settings": { "plugins.index_state_management.rollover_alias": "log" } } } -
创建带有
log别名的索引PUT log-000001 { "aliases": { "log": { "is_write_index": true } } } -
索引文档以触发翻转条件
POST log/_doc { "message": "dummy" } -
验证策略是否已附加到
log-000001索引GET _plugins/_ism/explain/log-000001?pretty
带有别名操作 ISM 模板的示例策略
以下示例策略适用于别名操作用例。
在以下示例中,第一个作业将触发翻转操作,并创建一个新索引。接下来,另一个文档被添加到这两个索引中。然后,新作业将导致第二个索引指向日志别名,并且较旧的索引将由于别名操作而被删除。
首先,创建一个 ISM 策略
PUT /_plugins/_ism/policies/rollover_policy?pretty
{
"policy": {
"description": "Example rollover policy.",
"default_state": "rollover",
"states": [
{
"name": "rollover",
"actions": [
{
"rollover": {
"min_doc_count": 1
}
}
],
"transitions": [{
"state_name": "alias",
"conditions": {
"min_doc_count": "2"
}
}]
},
{
"name": "alias",
"actions": [
{
"alias": {
"actions": [
{
"remove": {
"alias": "log"
}
}
]
}
}
]
}
],
"ism_template": {
"index_patterns": ["log*"],
"priority": 100
}
}
}
接下来,创建一个用于启用策略的索引模板
PUT /_index_template/ism_rollover?
{
"index_patterns": ["log*"],
"template": {
"settings": {
"plugins.index_state_management.rollover_alias": "log"
}
}
}
接下来,更改集群设置以每分钟触发作业
PUT /_cluster/settings?pretty=true
{
"persistent" : {
"plugins.index_state_management.job_interval" : 1
}
}
接下来,创建一个新索引
PUT /log-000001
{
"aliases": {
"log": {
"is_write_index": true
}
}
}
最后,向索引添加一个文档以触发作业
POST /log-000001/_doc
{
"message": "dummy"
}
您可以使用别名和索引 API 验证这些步骤
GET /_cat/indices?pretty
GET /_cat/aliases?pretty
注意:别名操作策略不允许使用 index 和 remove_index 参数。只允许使用 add 和 remove 别名操作参数。
示例策略
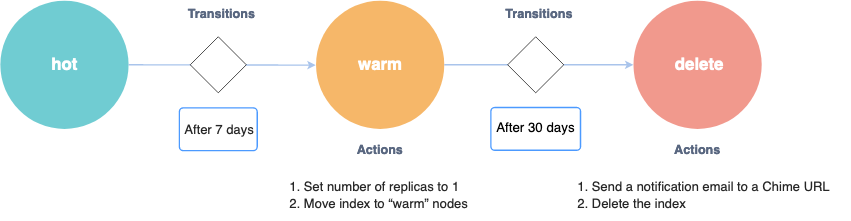
以下示例策略实现了 hot、warm 和 delete 工作流。您可以将此策略用作模板,根据索引的活动级别对其资源进行优先级排序。
在此示例中,索引最初处于 hot 状态。7 天后,它会更改为 warm 状态,其中副本数量减少到 1,索引会移动到具有 warm 属性的节点。
30 天后,策略会将此索引移动到 delete 状态。服务会向 Chime 聊天室发送通知,告知索引正在被删除,然后永久删除它。
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"states": [
{
"name": "hot",
"actions": [
{
"rollover": {
"min_index_age": "7d",
"min_primary_shard_size": "30gb"
}
}
],
"transitions": [
{
"state_name": "warm"
}
]
},
{
"name": "warm",
"actions": [
{
"replica_count": {
"number_of_replicas": 1
}
},
{
"allocation": {
"require": {
"temp": "warm"
}
}
}
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_index_age": "30d"
}
}
]
},
{
"name": "delete",
"actions": [
{
"notification": {
"destination": {
"chime": {
"url": "<URL>"
}
},
"message_template": {
"source": "The index {{ctx.index}} is being deleted"
}
}
},
{
"delete": {}
}
]
}
],
"ism_template": {
"index_patterns": ["log*"],
"priority": 100
}
}
}
此图显示了上述策略的 states、transitions 和 actions 作为有限状态机。有关有限状态机的更多信息,请参阅 Wikipedia。