OpenSearch 简介
OpenSearch 是一个分布式搜索和分析引擎,支持从在网站上实现搜索框到分析安全数据以进行威胁检测的各种用例。术语 分布式 意味着您可以在多台计算机上运行 OpenSearch。搜索和分析 意味着一旦将数据摄入 OpenSearch,就可以对其进行搜索和分析。无论您的数据类型如何,都可以使用 OpenSearch 存储和分析它。
文档
一个文档是存储信息(文本或结构化数据)的单元。在 OpenSearch 中,文档以 JSON 格式存储。
您可以从几个方面来理解文档
- 在学生数据库中,一个文档可能代表一个学生。
- 当您搜索信息时,OpenSearch 会返回与您的搜索相关的文档。
- 文档代表传统数据库中的一行。
例如,在学校数据库中,一个文档可能代表一个学生,并包含以下数据。
| ID | 名称 | GPA | 毕业年份 |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
以下是此文档的 JSON 格式示例
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
您将在索引文档中了解文档 ID 是如何分配的。
索引
一个索引是文档的集合。
您可以从几个方面来理解索引
- 在学生数据库中,一个索引代表数据库中的所有学生。
- 当您搜索信息时,您查询的是索引中包含的数据。
- 索引代表传统数据库中的一个表。
例如,在学校数据库中,一个索引可能包含学校中的所有学生。
| ID | 名称 | GPA | 毕业年份 |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
| 2 | Jonathan Powers | 3.85 | 2025 |
| 3 | Jane Doe | 3.52 | 2024 |
| … |
集群和节点
OpenSearch 被设计为一个分布式搜索引擎,这意味着它可以在一个或多个*节点*(存储数据和处理搜索请求的服务器)上运行。一个 OpenSearch *集群*是节点的集合。
您可以在笔记本电脑上本地运行 OpenSearch——其系统要求最低——但您也可以将单个集群扩展到数据中心中的数百台强大机器。
在单节点集群中,例如部署在笔记本电脑上的集群,一台机器必须执行所有任务:管理集群状态、索引和搜索数据,以及在索引数据之前执行任何数据预处理。然而,随着集群的增长,您可以细分职责。具有快速磁盘和充足 RAM 的节点在索引和搜索数据时可能表现良好,而具有充足 CPU 功率和小型磁盘的节点可以管理集群状态。
在每个集群中,都有一个选定的*集群管理器*节点,它协调集群级操作,例如创建索引。节点之间相互通信,因此如果您的请求被路由到一个节点,该节点会向其他节点发送请求,收集节点的响应,并返回最终响应。
有关其他节点类型的更多信息,请参阅集群形成。
分片
OpenSearch 将索引拆分为*分片*。每个分片存储索引中所有文档的一个子集,如下图所示。
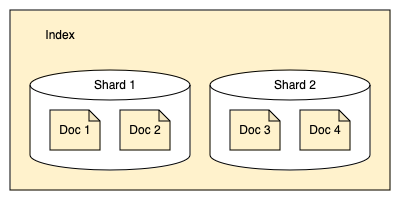
分片用于集群中节点的均匀分布。例如,一个 400 GB 的索引可能对于集群中的任何单个节点来说都太大了,但如果将其拆分为 10 个各 40 GB 的分片,OpenSearch 就可以将这些分片分布到 10 个节点上,并单独管理每个分片。考虑一个包含 2 个索引的集群:索引 1 和索引 2。索引 1 被拆分为 2 个分片,索引 2 被拆分为 4 个分片。这些分片分布在节点 1 和节点 2 上,如下图所示。
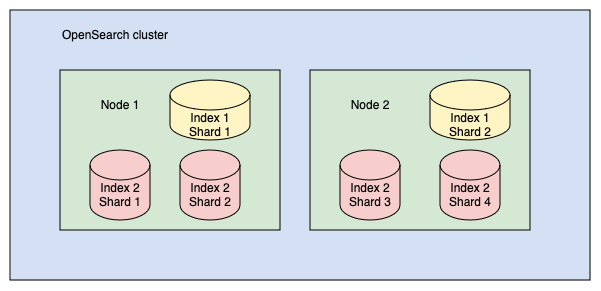
尽管每个分片都是 OpenSearch 索引的一部分,但它实际上是一个完整的 Lucene 索引。这个细节很重要,因为 Lucene 的每个实例都是一个正在运行的进程,会消耗 CPU 和内存。分片越多不一定越好。例如,将一个 400 GB 的索引拆分为 1,000 个分片,会不必要地增加集群的负担。一个好的经验法则是将分片大小限制在 10–50 GB。
主分片和副本分片
在 OpenSearch 中,分片可以是*主*(原始)分片或*副本*(拷贝)分片。默认情况下,OpenSearch 为每个主分片创建一个副本分片。因此,如果您将索引拆分为 10 个分片,OpenSearch 会创建 10 个副本分片。例如,考虑上一节中描述的集群。如果您为集群中每个索引的每个分片添加 1 个副本,则您的集群将总共包含索引 1 的 2 个分片和 2 个副本,以及索引 2 的 4 个分片和 4 个副本,如下图所示。
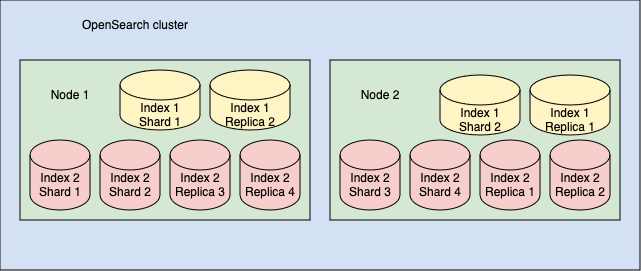
这些副本分片在节点故障时充当备份——OpenSearch 将副本分片分布到与相应主分片不同的节点上——但它们也提高了集群处理搜索请求的速度。对于搜索密集型工作负载,您可以为每个索引指定多个副本。
倒排索引
OpenSearch 索引使用一种称为*倒排索引*的数据结构。倒排索引将词语映射到它们出现的文档。例如,考虑一个包含以下两个文档的索引
- 文档 1:“Beauty is in the eye of the beholder”
- 文档 2:“Beauty and the beast”
此类索引的倒排索引将词语映射到它们出现的文档
| 词语 | 文档 |
|---|---|
| beauty | 1, 2 |
| is | 1 |
| in | 1 |
| the | 1, 2 |
| eye | 1 |
| of | 1 |
| beholder | 1 |
| and | 2 |
| beast | 2 |
除了文档 ID,OpenSearch 还存储词语在文档中的位置,以便运行短语查询,其中词语必须彼此相邻出现。
相关性
当您搜索文档时,OpenSearch 会将查询中的词语与文档中的词语进行匹配。例如,如果您在上一节描述的索引中搜索词语 beauty,OpenSearch 将返回文档 1 和 2。每个文档都被赋予一个*相关性得分*,它告诉您文档与查询匹配的程度。
搜索查询中的单个词语称为搜索*术语*。每个搜索术语根据以下规则进行评分
-
在文档中出现频率更高的搜索术语往往会获得更高的分数。一篇多次使用词语
dog的关于狗的文档可能比一篇包含该词语次数较少的文档更具相关性。这是得分的词频组成部分。 -
在更多文档中出现的搜索术语往往会获得较低的分数。对术语
blue和axolotl的查询应优先选择包含axolotl的文档,而不是可能更常见的词语blue。这是得分的逆文档频率组成部分。 -
较长文档上的匹配得分应低于较短文档上的匹配得分。包含完整字典的文档可以匹配任何词语,但与任何特定词语的相关性不大。这对应于得分的长度归一化组成部分。
OpenSearch 使用 BM25 排名算法计算文档相关性得分,然后按相关性排序返回结果。要了解更多信息,请参阅Okapi BM25。
后续步骤
- 在快速安装指南中了解如何在几分钟内安装 OpenSearch。