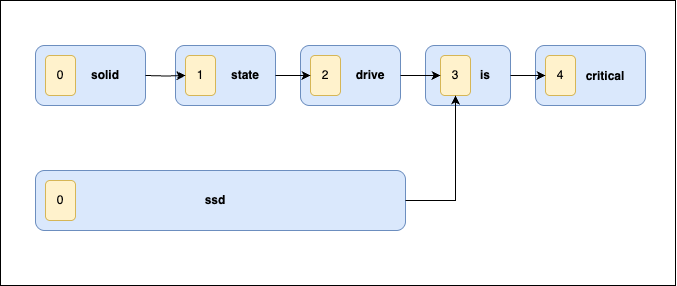
令牌图
Token 图显示了在文本分析过程中 token 之间如何相互关联,尤其是在处理多词同义词或复合词时。它们有助于确保准确的查询匹配和短语扩展。
每个 token 都被分配以下元数据:
-
position– token 在文本中的位置 -
positionLength– token 跨越的position数量(用于多词表达式)
Token 图使用这些信息来构建 token 关系图结构,该结构稍后在查询解析期间使用。图感知 token 过滤器,例如 synonym_graph 和 word_delimiter_graph,使您能够更准确地匹配短语。
下图描绘了使用 synonym_graph 时 position 和 positionLength 之间的关系。“NYC” token 被分配了一个 position 为 0 和一个 positionLength 为 3。
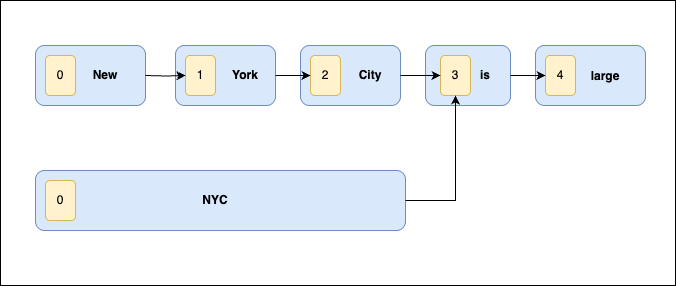
在索引和查询期间使用 token 图
在索引时,positionLength 被忽略,并且不使用 token 图。
在查询执行期间,各种查询类型可以利用 token 图,其中以下是最常用的:
示例:同义词与同义词图的比较
为了更好地理解图感知 token 过滤器和标准 token 过滤器之间的区别,您可以使用以下步骤比较 synonym token 过滤器和 synonym_graph token 过滤器:
-
创建一个带有
synonymtoken 过滤器(非图感知)的索引PUT /synonym_index { "settings": { "analysis": { "filter": { "my_synonyms": { "type": "synonym", "synonyms": ["ssd => solid state drive"] } }, "analyzer": { "my_analyzer": { "tokenizer": "standard", "filter": ["lowercase", "my_synonyms"] } } } }, "mappings": { "properties": { "content": { "type": "text", "analyzer": "my_analyzer" } } } } -
创建一个带有
synonym_graphtoken 过滤器(图感知)的索引PUT /synonym_graph_index { "settings": { "analysis": { "filter": { "my_synonyms": { "type": "synonym_graph", "synonyms": ["ssd => solid state drive"] } }, "analyzer": { "my_analyzer": { "tokenizer": "standard", "filter": ["lowercase", "my_synonyms"] } } } }, "mappings": { "properties": { "content": { "type": "text", "analyzer": "my_analyzer" } } } } -
在每个索引中创建相同的文档
PUT /synonym_index/_doc/1 { "content": "ssd is critical" }PUT /synonym_graph_index/_doc/1 { "content": "ssd is critical" } -
搜索非图感知索引
POST /synonym_index/_search { "query": { "match_phrase": { "content": "solid state drive is critical" } } }响应中没有匹配项
{ "took": 13, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 0, "relation": "eq" }, "max_score": null, "hits": [] } } -
搜索图感知索引
POST /synonym_graph_index/_search { "query": { "match_phrase": { "content": "solid state drive is critical" } } }响应中包含一个匹配项
{ "took": 9, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1.4384103, "hits": [ { "_index": "synonym_graph_index", "_id": "1", "_score": 1.4384103, "_source": { "content": "ssd is critical" } } ] } }
使用图感知 token 过滤器时会出现匹配,因为在 match_phrase 查询期间,会使用 token 图生成一个额外的子查询。下图说明了由图感知 token 过滤器创建的 token 图。